
Недавно мое внимание привлек факт, что в обновлениях прошивок для Linksys WRT120N используют какую-то обфускацию. Мне показалось, что будет интересно порыться в ней, и я решил взглянуть.
Последняя версия прошивки не выглядит как прошивка, с которой можно сразу работать
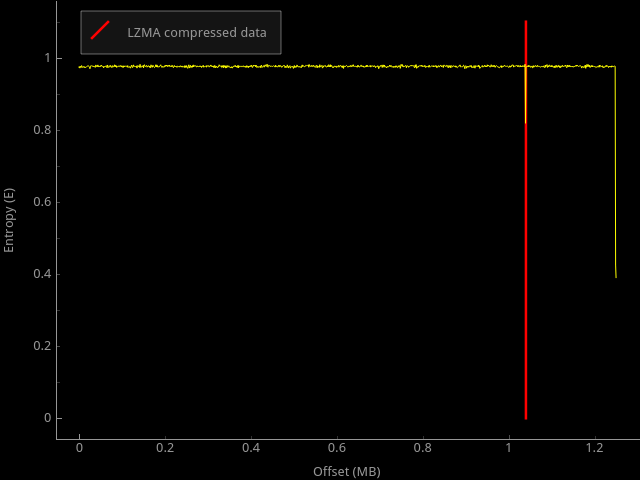
Как вы можете видеть, есть небольшой блок данных, сжатых LZMA — это просто HTML-файлы для веб-интерфейса роутера. Большая часть прошивки состоит из каких-то странных, случайных данных. Т.к. мне больше ничего с ней не сделать, а любопытство все сильнее пыталось одолеть меня, я купил эту модель роутера себе (как они стоимость Amazon Prime-то взвинтили!).
Последняя версия прошивки не выглядит как прошивка, с которой можно сразу работать
Как вы можете видеть, есть небольшой блок данных, сжатых LZMA — это просто HTML-файлы для веб-интерфейса роутера. Большая часть прошивки состоит из каких-то странных, случайных данных. Т.к. мне больше ничего с ней не сделать, а любопытство все сильнее пыталось одолеть меня, я купил эту модель роутера себе (как они стоимость Amazon Prime-то взвинтили!).
 В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.
В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.
 От переводчика
От переводчика 



 Если и есть что-то, что веб-разработчики любят, так это знать что-то, что лучше традиционного. Но традиционное является таковым по одной причине: это дерьмо работает. Что-то давно беспокоило меня во всей этой шумихе вокруг Node.js, но у меня не было времени разобраться, что именно, пока я не прочитал
Если и есть что-то, что веб-разработчики любят, так это знать что-то, что лучше традиционного. Но традиционное является таковым по одной причине: это дерьмо работает. Что-то давно беспокоило меня во всей этой шумихе вокруг Node.js, но у меня не было времени разобраться, что именно, пока я не прочитал 