
На Хабре уже не раз и не два обращались к теме поддержания физической формы, для такой профессии как айтишник, админ и тому подобные властители неведомого серверного оборудования.
Были темы и просто о пользе бега, со стандартной теоретической подготовкой, и о маленьком, но хитром специальном устройстве от Nike, украшающем беговой процесс. Однако нас, как людей технических до мозга костей, интересует иное: можно ли в процессе беговой тренировки, использовать всю мощь технического прогресса для достижения максимальных результатов?
Поэтому данная статья больше перекликается с давним описанием: нескольких беговых девайсов, с учетом прошедших лет и текущего положения дел в области приборов для спорта и бега.
Все, что описано в статье, испытано на собственном опыте, все скриншоты и результаты взяты из личных данных.
Исходные данные: один условный «айтишник», перешагнувший рубеж 30 лет, и 90 кг.
Необходимо: заинтересовать техногика простыми тренировками, помогающими сохранить физическую форму, сбросить вес и укрепить сердце.

Были темы и просто о пользе бега, со стандартной теоретической подготовкой, и о маленьком, но хитром специальном устройстве от Nike, украшающем беговой процесс. Однако нас, как людей технических до мозга костей, интересует иное: можно ли в процессе беговой тренировки, использовать всю мощь технического прогресса для достижения максимальных результатов?
Поэтому данная статья больше перекликается с давним описанием: нескольких беговых девайсов, с учетом прошедших лет и текущего положения дел в области приборов для спорта и бега.
Все, что описано в статье, испытано на собственном опыте, все скриншоты и результаты взяты из личных данных.
Исходные данные: один условный «айтишник», перешагнувший рубеж 30 лет, и 90 кг.
Необходимо: заинтересовать техногика простыми тренировками, помогающими сохранить физическую форму, сбросить вес и укрепить сердце.
 После трёх лет работы со студийным светом я думал, что знаю про накамерную вспышку если не всё, то очень много. Три недели назад я попал в гости к одному особо опытному стробисту, который рассказал и показал столько, что я сразу понял, что надо садиться и делать перепись грабель, а потом тестить, тестить и ещё раз тестить.
После трёх лет работы со студийным светом я думал, что знаю про накамерную вспышку если не всё, то очень много. Три недели назад я попал в гости к одному особо опытному стробисту, который рассказал и показал столько, что я сразу понял, что надо садиться и делать перепись грабель, а потом тестить, тестить и ещё раз тестить. 



 Profile-guided optimization (далее PGO) — техника оптимизации программы компилятором, нацеленная на увеличение производительности выполнения программы. В отличии от традиционных способов оптимизации анализирующих исключительно исходные коды, PGO использует результаты измерений тестовых запусков оптимизируемой программы для генерации оптимального кода.
Profile-guided optimization (далее PGO) — техника оптимизации программы компилятором, нацеленная на увеличение производительности выполнения программы. В отличии от традиционных способов оптимизации анализирующих исключительно исходные коды, PGO использует результаты измерений тестовых запусков оптимизируемой программы для генерации оптимального кода.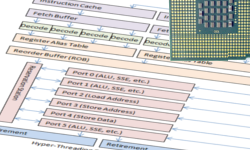 Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.