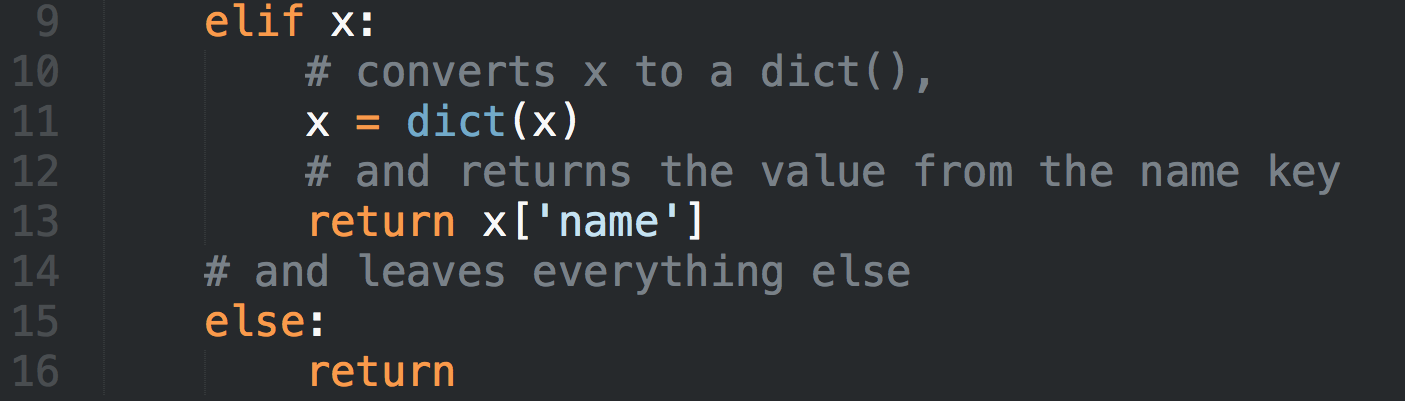
Содержание
- Вопросы и ответы
- Введение
- 1.0 Играем с Busybox
- 2.0 Веб-приложения и Докер
- 3.0 Многоконтейнерные окружения
- 4.0 Заключение
Вопросы и ответы
Что такое Докер?
Определение Докера в Википедии звучит так:
программное обеспечение для автоматизации развёртывания и управления приложениями в среде виртуализации на уровне операционной системы; позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, а также предоставляет среду по управлению контейнерами.
Ого! Как много информации.





 Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.
Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.



 Вчера в Госдуму
Вчера в Госдуму