
Изучаем оптический SFP трансивер. Рассматриваем его внутреннее устройство, элементный состав, электрические подключения. Для закрепления материала попробуем отправить и принять сообщение по оптоволокну, используя платформу Arduino.

User
Изучаем оптический SFP трансивер. Рассматриваем его внутреннее устройство, элементный состав, электрические подключения. Для закрепления материала попробуем отправить и принять сообщение по оптоволокну, используя платформу Arduino.
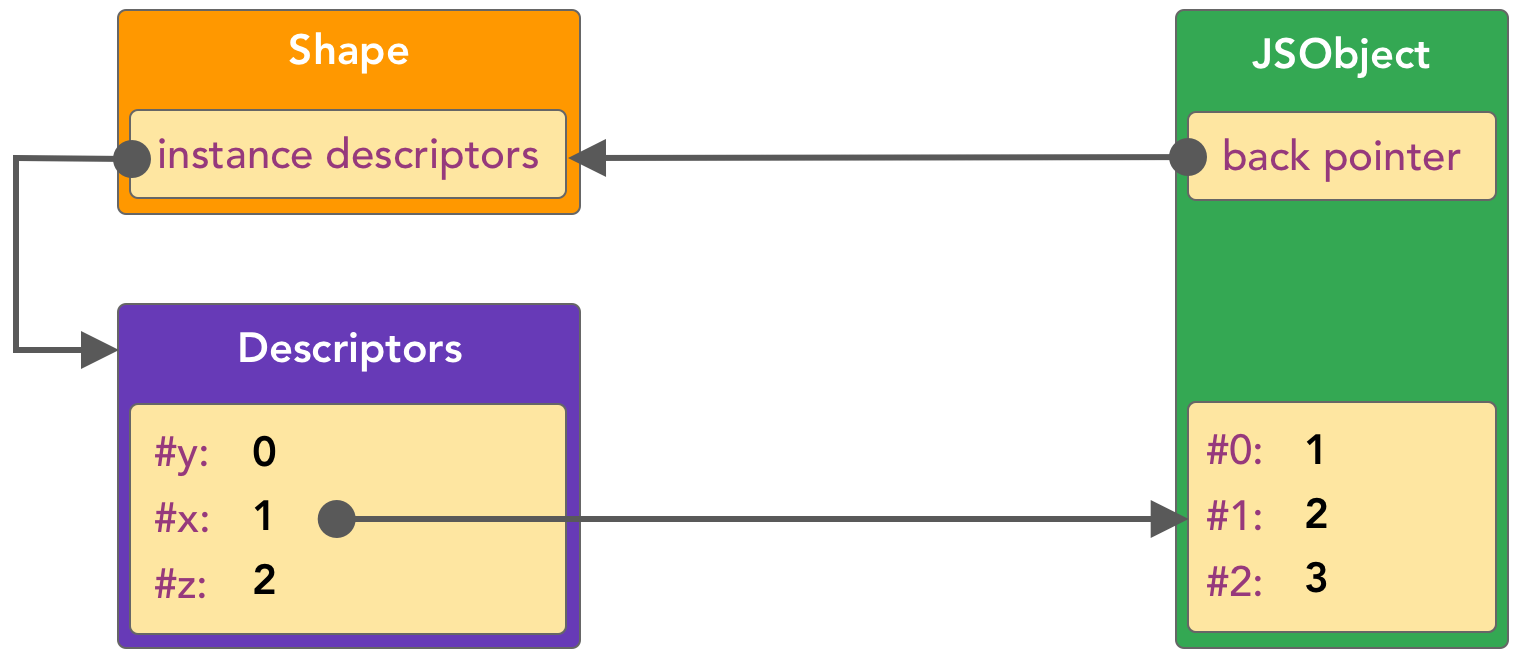
Думаю, ни для кого не секрет, что все популярные JavaScript движки имеют схожий пайплайн выполнения кода. Выглядит он примерно следующим образом. Интерпретатор быстро компилирует JS-код в байт "на лету". Полученный байт код начинает исполняться и параллельно обрабатывается оптимизатором. Оптимизатору требуется время на такую обработку, но в итоге может получиться высоко-оптимизированный код, который будет работать в разы быстрее. В движке V8 роль интерпретатора выполняет Ignition, а оптимизатором является Turbofan. В движке Chakra, который используется в Edge, вместо одного оптимизатора целых два, SimpleJIT и FullJIT. А в JSC (Safari), аж три Baseline, DFG и FTL. Конкретная реализация в разных движка может отличаться, но принципиальная схема, в целом одинакова.
Сегодня мы будем говорить об одном из множества механизмов оптимизации, который называется Inline Caches.


Приветствую, Хабр!
В статье хочу показать процесс снятия чипов в BGA корпусе и установки на новую плату не перекатывая шарики. Опишу некоторые нюансы, которые позволяют осуществлять данную операцию более или менее безболезненно.


Почти каждый, кто хоть раз ставил ROOT-права на Android, слышал про такой файл как build.prop и твики для него. В этой статье мы рассмотрим все строки данного файла с помощью которых можно улучшить качество звучания смартфона и включить полезные функции, которые были отключены по умолчанию в системе.

Некоторые IDE и текстовые редакторы парсят исходный файл целиком при каждом изменении, что может тормозить на больших файлах, а некоторые делают это построчно с помощью регулярных выражений, что тоже тормозит и не даёт качественной подсветки кода, т.к. теряется контекст. Для решения этих проблем в недрах GitHub был создан tree-sitter - инкрементальный парсер, который используют всё больше и больше проектов. Давайте разбираться зачем и почему.
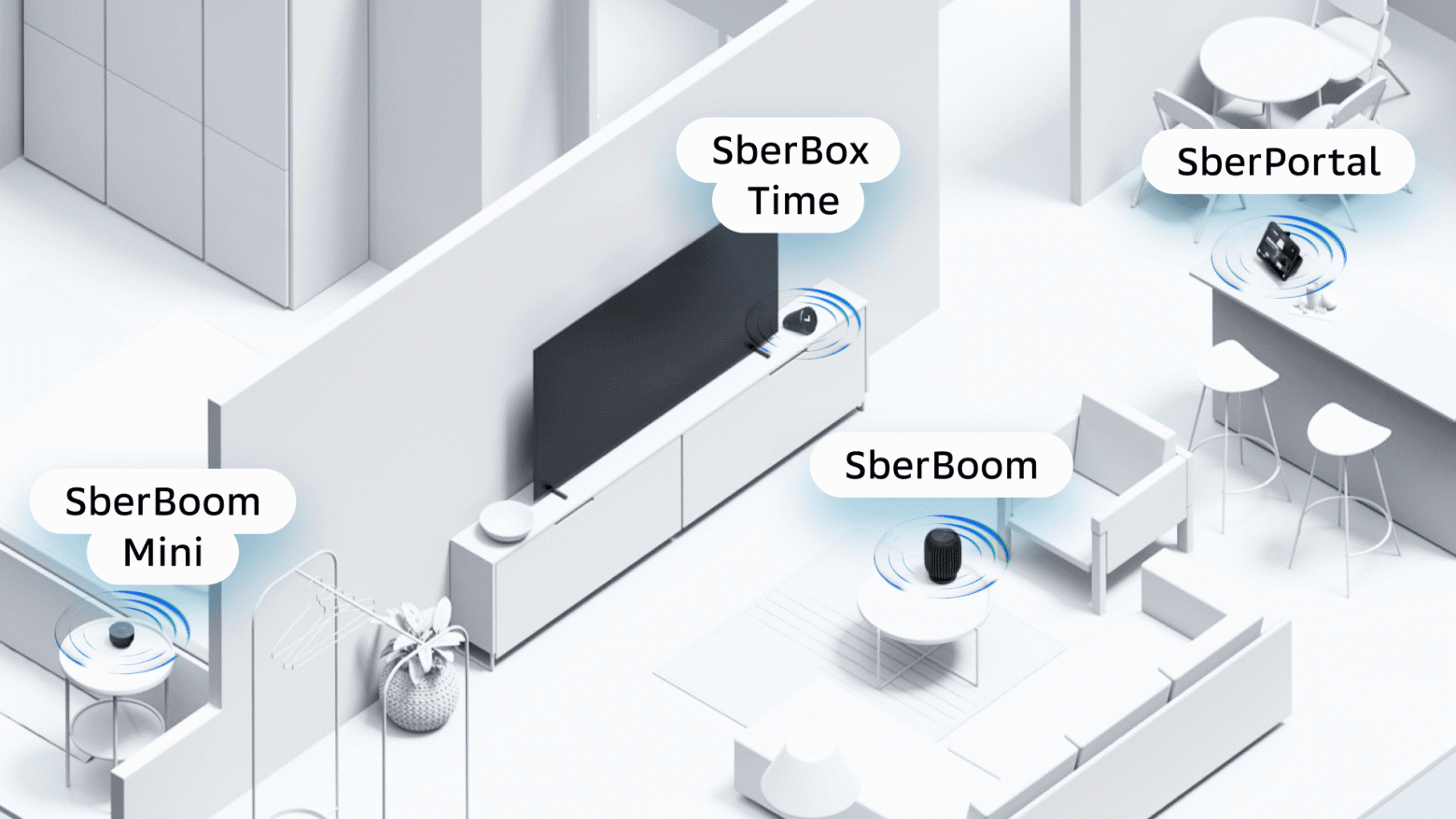
В феврале 2023 года на части устройств SberDevices мы анонсировали поддержку двух новых режимов работы — Мультирум и Стереопара.
Мультирум позволяет прослушивать музыку на нескольких устройствах различного типа одновременно. Например, колонка SberBoom может находиться в спальне, а SberPortal — в гостиной, и в таком режиме музыка на этих устройствах будет играть синхронно. Стереопара отличается от Мультирума тем, что в Cтереопаре могут участвовать только две одинаковые колонки, при этом устройства, воспроизводя звук так же синхронно, делят его на каналы — левый и правый (каждое устройство проигрывает свой канал), в зависимости от выбранных пользователем настроек.
От этапа идеи до выхода в продакшн прошел примерно год, после чего уже столько же времени вышеупомянутые фичи используются нашими пользователями. За это время мы провели ряд исследований. Было много попыток исправить различные баги, большинство из которых увенчались успехом, также случались и тупиковые ветви направления развития.
В этой статье мы с коллегами @kpvf2dи @Alergenхотим поделиться и, возможно, обсудить некоторые проблемы и их решения.
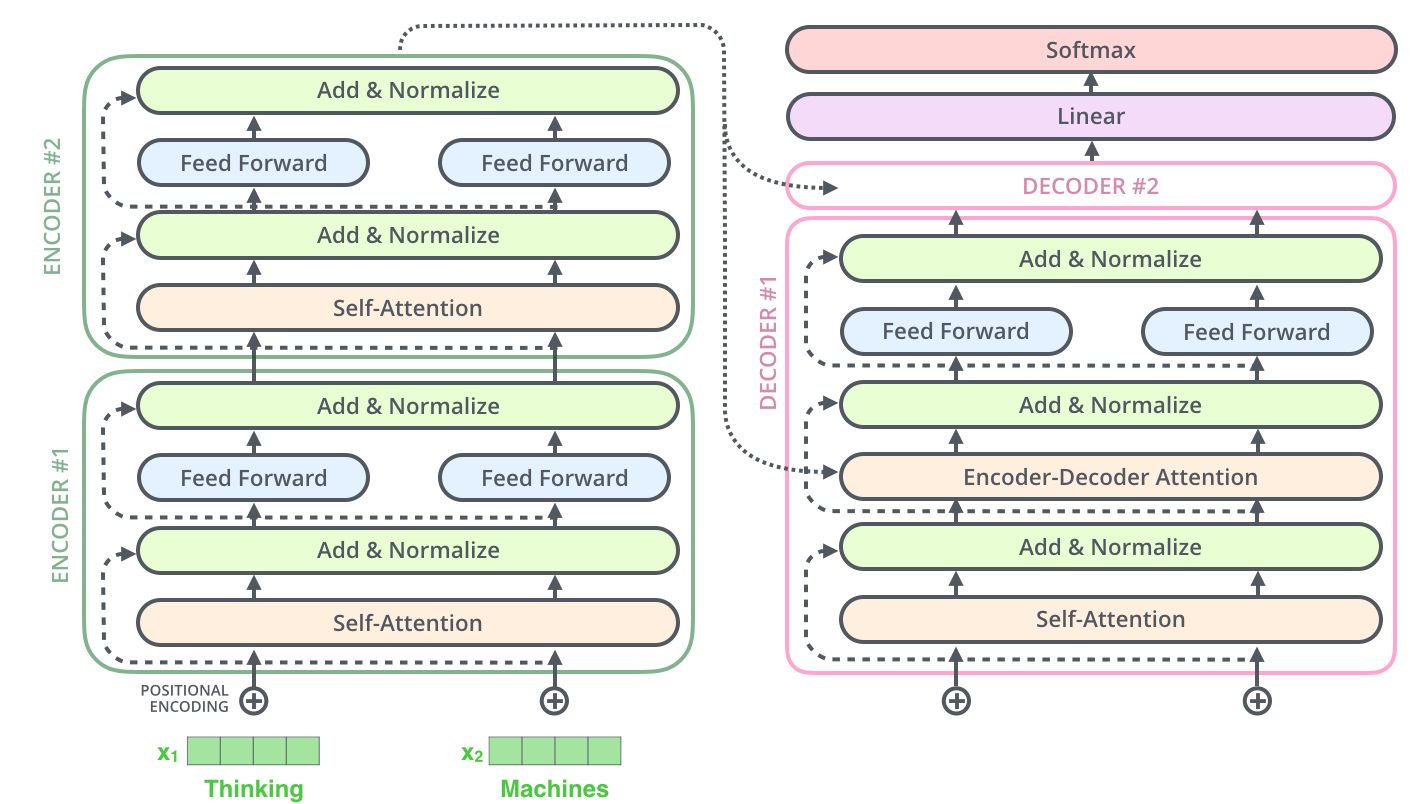
В этом посте я представлю подробный пример математики, используемой внутри модели трансформера, чтобы вы получили хорошее представление о работе модели. Чтобы пост был понятным, я многое упрощу. Мы будем выполнять довольно много вычислений вручную, поэтому снизим размерность модели. Например, вместо эмбеддингов из 512 значений мы используем эмбеддинги из 4 значений. Это позволит упростить понимание вычислений. Мы используем произвольные векторы и матрицы, но при желании вы можете выбрать собственные значения.
Как вы увидите, математика модели не так уж сложна. Сложность возникает из-за количества этапов и количества параметров. Перед прочтением этой статьи я рекомендую прочитать пост Illustrated Transformer (или читать их параллельно) [перевод на Хабре]. Это отличный пост, объясняющий модель трансформера интуитивным (и наглядным!) образом, поэтому я не буду объяснять то, что уже объяснено в нём. Моя цель заключается в том, чтобы объяснить, как работает модель трансформера, а не что это такое. Если вы хотите углубиться в подробности, то изучите известную статью Attention is all you need [перевод на Хабре: первая и вторая части].

60 строках numpy. Во второй части статьи мы загрузим в нашу реализацию опубликованные OpenAI веса обученной модели GPT-2 и сгенерируем текст.
В минувшем году все только и говорили об ИИ и о том, как он может всё за вас сделать.
Мне нравится, когда кто-то или что-то работает за меня. Поэтому решил: попрошу-ка ChatGPT написать за меня новогодний пост:
«Эй, ChatGPT. А ты можешь реализовать большую языковую модель на SQL?»
«Нет, SQL не подходит для реализации больших языковых моделей. Язык SQL предназначен для выполнения запросов к данным, хранящимся в РСУБД и для управления этими запросами. Для реализации большой языковой модели требуются сложные алгоритмы, обширные датасеты, а зачастую — и фреймворки для глубокого обучения. SQL всеми этими возможностями не обладает.»
Что ж, лишний раз убеждаешься, что, если хочешь что‑то сделать хорошо – сделай это сам.
Давайте же воодушевимся этим оптимистическим планом и реализуем большую языковую модель на языке SQL.

Для завершения реализации компилятора потребовалось около месяца времени (вечерами), чтобы на практике познакомиться с такими темами как BNF (Backus Naur Form), Abstract Syntax Tree (AST), Symbol Table, способами генерации кода, разработки самого компилятора (front-end, back-end), а также модификации виртуальной машины CVM. Ранее с этими темами был не знаком, но благодаря комментаторам погрузился. Хоть затрагиваемых тем много, постараюсь рассказать очень лаконично. Но обо всём по порядку.
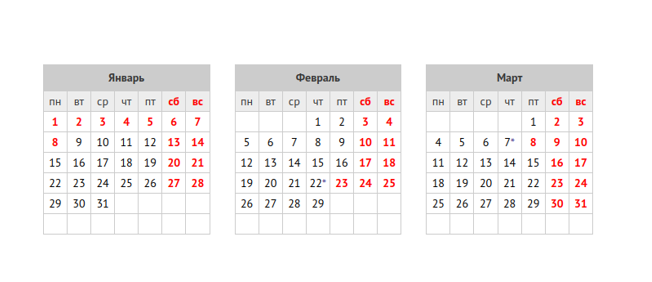
Новый Год уже совсем на носу, а значит нужен свежий производственный календарь в базе данных PostgreSQL. Но как совершенно обленившийся IT-шник, заводить его руками не хочется. Хочется, чтобы вызовом одной функции он сразу появился. Ну а уж из этой функции можно его сохранить в табличку и спокойно использовать до следующего Нового Года. А тогда опять просто вызвать вызвать функцию и с чистой совестью отрапортовать о выполненной работе. Цель статьи - показать возможности COPY ... FROM PROGRAM и простейшие приемы парсинга XML в PostgreSQL.


Полное руководство. Как я вступал, как подавал заявку на повышение грейда, как её рассматривали, на что обращают внимание ревьюверы, и как я потом подтверждал своё членство для получения грин-карты.
Есть много локальных аналогов ChatGPT, но им не хватает качества, даже 65B модели не могут конкурировать хотя бы с ChatGPT-3.5. И здесь я хочу рассказать про 2 открытые модели, которые всё-таки могут составить такую конкуренцию.
Речь пойдет о OpenChat 7B и DeepSeek Coder. Обе модели за счет размера быстры, можно запускать на CPU, можно запускать локально, можно частично ускорять на GPU (перенося часть слоев на GPU, на сколько хватит видеопамяти) и для такого типа моделей есть графический удобный интерфейс.
И бонусом затронем новую модель для качественного подробного описания фото.
UPD: Добавлена информация для запуска на Windows с ускорением на AMD.

В этой статье я расскажу о нашей последней работе — Multilingual Triple Match — системе для поиска ответов на фактологические вопросы, которая по своей точности обходит даже ChatGPT.

В этой статье мы научимся писать полноценный gRPC сервис на Go на примере сервера авторизации с полноценной архитектурой, готовой к продакшену. Мы напишем как серверную часть, так и клиентскую. В качестве клиента мы возьмём мой сервис — URL Shortener, о котором у меня также есть статья и видео-гайд на ютубе. Попутно мы познакомимся с базовыми подходами к работе с авторизацией. И в конце настроим автоматический деплой сервиса с помощью GitHub Actions на удалённый сервер.
Видео-версия этого гайда с более подробными объяснениями
Исходный код проекта: https://github.com/GolangLessons/sso
Итого, наш план:
На выходе мы получим полноценный рабочий сервис авторизации, который вы сможете по аналогии подключать к своим пет-проектам.
Кратко обо мне: меня зовут Николай Тузов, я много лет занимаюсь разработкой на Go, очень люблю этот язык. Также веду свой YouTube-канал.
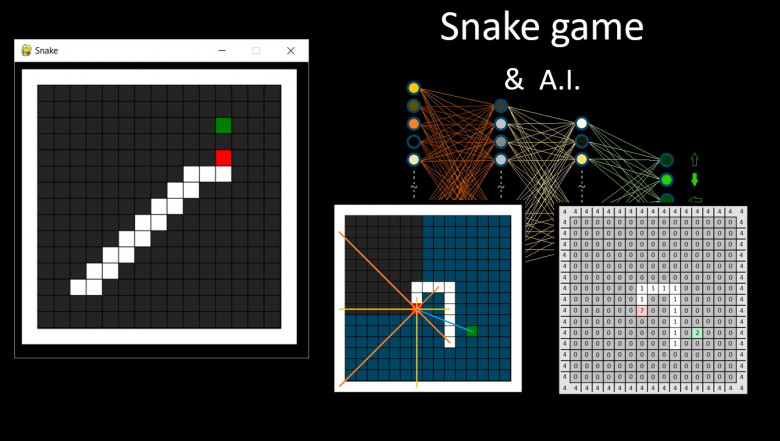
В 2020, когда случился локдаун, и к большому сожалению, появилось очень много свободного времени, мне захотелось познакомиться с Python. Начальный опыт c Pascal был еще со школы и универа, поэтому оставалось лишь придумать задачу и пойти её самоотверженно решать на питоне. Интересной задачей показалось смастерить игру змейку, прикрутить к ней мозги в виде перцептрона с парой скрытых слоёв, и путем кнута и яблока обучить цифровое животное выживать в жестоких реалиях двумерного мира :)
«У самурая нет цели, есть только путь»
Первый блин на производстве не отличается красотой, но опыт был получен. Наиболее привлекательным мне пришелся генетический алгоритм: отбор успешных змеек, скрещивание, частичная мутация генов и так тысячи раз до результата. Змейки, без указания им правил выживания, в тысячном поколении «понимали», что нужно стремиться съесть яблоко и никуда не врезаться, это вызывало ощущение прикосновения к чуду "It's Alive!!!"
Спустя пару лет, закончив курс по аналитике данных, появилось желание переписать проект, попрактиковаться в более серьезных разделах python и сделать тренажёр со сбором статистики.

Несколько лет назад я полностью перешел на Linux, и все меня устраивало за исключением отсутствия некоторых просто необходимых программ.