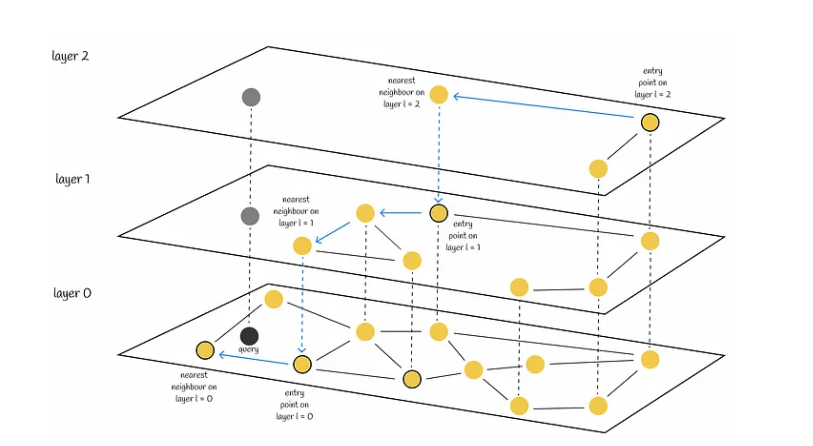
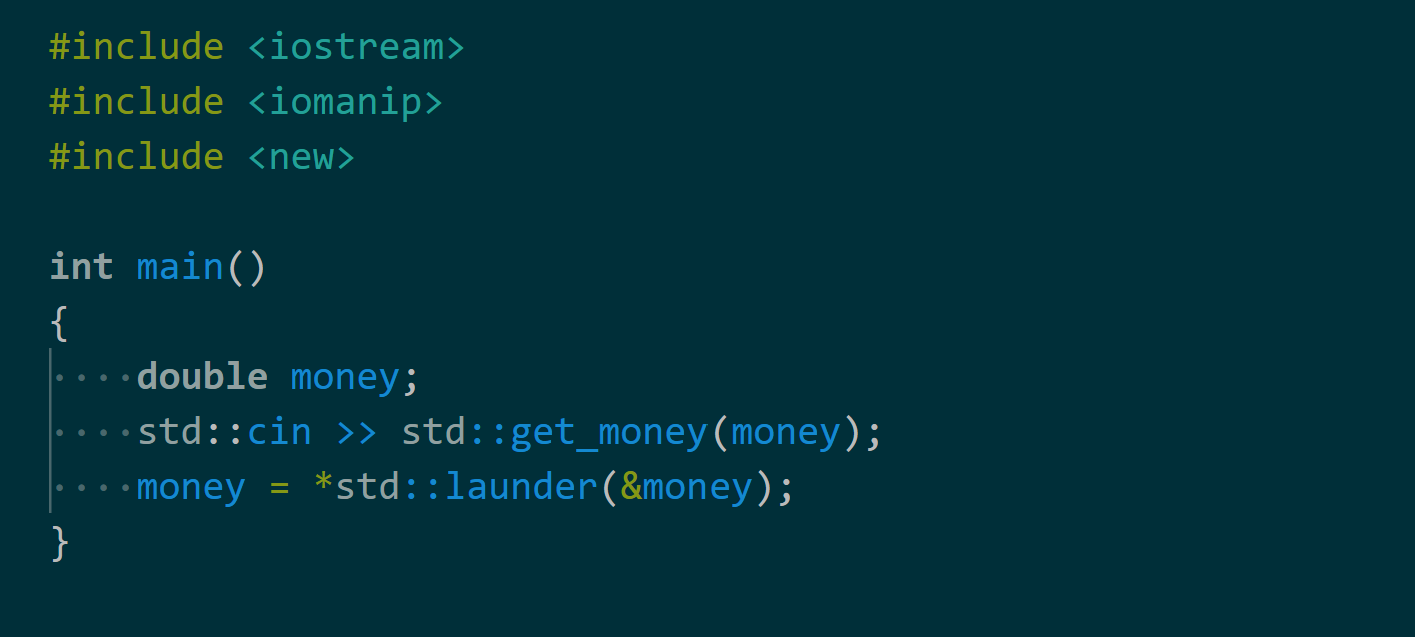
Представьте себе: обнаружен бэкдор в OpenSSH, мейнтейнеры спешат выпустить релиз с исправлениями, исследователи безопасности обмениваются техническими деталями, чтобы проанализировать вредоносный код. Разгораются обсуждения по поводу причастности и мотивов злоумышленника, а технические СМИ бросаются освещать историю. Почти что эпическое происшествие, удар по доверию, лежащему в основе разработки с открытым исходным кодом, яркое напоминание о рисках атак на цепочки поставок. В равной мере блестяще и коварно.
Если вы следите за новостями безопасности, то, возможно, сразу вспомните атаку на репозиторий liblzma/xz‑utils в начале этого года, конечной целью которой был бэкдор в OpenSSH. Однако ниже мы обсудим не случай с xz‑utils, ведь мало кто помнит, что бэкдор в xz‑utils на самом деле второй широко известной попыткой внедрения бэкдора в OpenSSH. Впервые это произошло более 22 лет назад, в 2002 году. Эта статья рассказывает историю того бэкдора и тому, чему можно научиться из атаки, произошедшей более двух десятилетий назад.