Нашим глазам пришлось пойти на жертвы, чтобы помочь нам выжить

Большая часть млекопитающих полагается на обоняние больше, чем на зрение. Посмотрите на собачьи глаза – они расположены по бокам морды, не так, как у людей, у которых они находятся близко и направлены вперёд. Глаза по бокам позволяют увеличить область обзора, но плохо передают ощущению глубины и расстояние до объектов. Вместо хорошего зрения у собак, лошадей, мышей, антилоп – и в принципе у большинства млекопитающих – есть длинные влажные носы. Отличаемся от них мы, люди, человекообразные и обычные обезьяны. И у нашего зрения есть определённая необычная особенность, которую необходимо объяснить.
Со временем, занимая более освещённые экологические ниши, мы стали всё меньше полагаться на запах и всё больше на зрение. Мы потеряли влажные носы и рыльца, наши глаза подвинулись вперёд на лице и сблизились друг с другом, что улучшило наше умение оценивать расстояние (мы выработали улучшенное бинокулярное зрение). Кроме того, обезьяны Старого Света, или узконосые обезьяны,
catarrhini, выработали трихроматизм: цветное зрение из красного, зелёного и синего. У большинства других млекопитающих в глазах содержится два разных типа фоторецепторов (колбочек), но предок узконосых обезьян перенёс
дупликацию генов, что создало три разных гена для цветового зрения. Каждый из них кодирует фоторецептор, настроенный на свет разных длин волн: короткие (синий), средние (зелёный) и длинные (красный). Итак, наши предки в результате эволюции выработали глаза, смотрящие вперёд и трихроматическое зрение – и больше мы не оглядывались.







 Зачем эта статья?
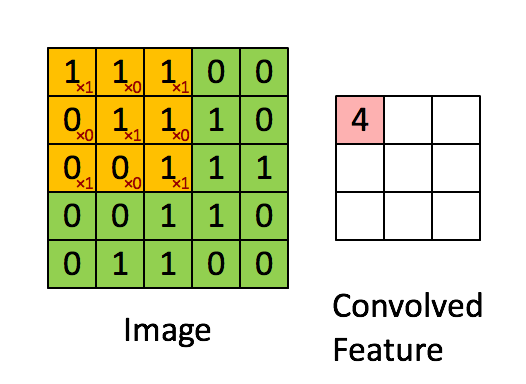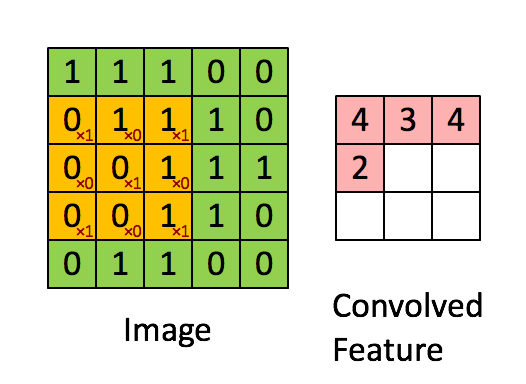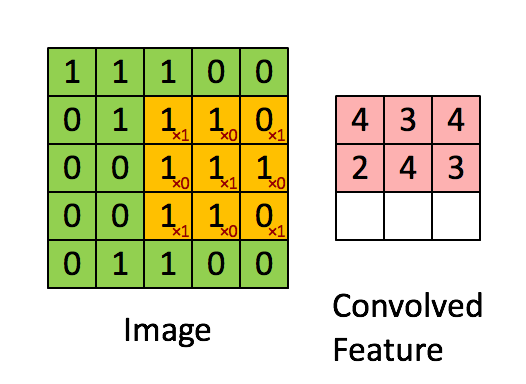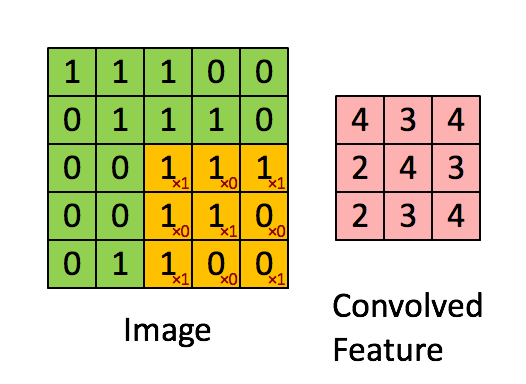
Зачем эта статья? Есть в технических кругах шутка, что «Большие данные» это данные, для обработки которых недостаточно Excel 2010 на мощном ноутбуке. То есть если для решения задачи вам надо оперировать 1 миллионом строк на листе и более или 16 тысяч столбцов и более, то поздравляем, ваша данные относятся к разряду «Больших».
Есть в технических кругах шутка, что «Большие данные» это данные, для обработки которых недостаточно Excel 2010 на мощном ноутбуке. То есть если для решения задачи вам надо оперировать 1 миллионом строк на листе и более или 16 тысяч столбцов и более, то поздравляем, ваша данные относятся к разряду «Больших».


