
Since the PostgreSQL 17 RC1 came out, we are on a home run towards the official PostgreSQL release, scheduled for September 26, 2024.
Let's take a look at the patches that came in during the March CommitFest.

Технический писатель
Since the PostgreSQL 17 RC1 came out, we are on a home run towards the official PostgreSQL release, scheduled for September 26, 2024.
Let's take a look at the patches that came in during the March CommitFest.

The November commitfest is ripe with new interesting features! Without further ado, let's proceed with the review.
If you missed our July and September commitfest reviews, you can check them out here: 2023-07, 2023-09.
ON LOGIN trigger
Event triggers for REINDEX
ALTER OPERATOR: commutator, negator, hashes, merges
pg_dump --filter=dump.txt
psql: displaying default privileges
pg_stat_statements: track statement entry timestamps and reset min/max statistics
pg_stat_checkpointer: checkpointer process statistics
pg_stats: statistics for range type columns
Planner: exclusion of unnecessary table self-joins
Planner: materialized CTE statistics
Planner: accessing a table with multiple clauses
Index range scan optimization
dblink, postgres_fdw: detailed wait events
Logical replication: migration of replication slots during publisher upgrade
Replication slot use log
Unicode: new information functions
New function: xmltext
AT LOCAL support
Infinite intervals
ALTER SYSTEM with unrecognized custom parameters
Building the server from source

We continue to follow the news of the PostgreSQL 17 development. Let's find out what the September commitfest brings to the table.
If you missed our July commitfest review, you can check it out here: 2023-07.
Removed the parameter old_snapshot_threshold
New parameter event_triggers
New functions to_bin and to_oct
New system view pg_wait_events
EXPLAIN: a JIT compilation time counter for tuple deforming
Planner: better estimate of the initial cost of the WindowAgg node
pg_constraint: NOT NULL constraints
Normalization of CALL, DEALLOCATE and two-phase commit control commands
unaccent: the target rule expressions now support values in quotation marks
COPY FROM: FORCE_NOT_NULL * and FORCE_NULL *
Audit of connections without authentication
pg_stat_subscription: new column worker_type
The behaviour of pg_promote in case of unsuccessful switchover to a replica
Choosing the disk synchronization method in server utilities
pg_restore: optimization of parallel recovery of a large number of tables
pg_basebackup and pg_receivewal with the parameter dbname
Parameter names for a number of built-in functions
psql: \watch min_rows

We continue to follow the news in the world of PostgreSQL. The PostgreSQL 16 Release Candidate 1 was rolled out on August 31. If all is well, PostgreSQL 16 will officially release on September 14.
What has changed in the upcoming release after the April code freeze? What's getting into PostgreSQL 17 after the first commitfest? Read our latest review to find out!

The end of the March Commitfest concludes the acceptance of patches for PostgreSQL 16. Let’s take a look at some exciting new updates it introduced.
I hope that this review together with the previous articles in the series (2022-07, 2022-09, 2022-11, 2023-01) will give you a coherent idea of the new features of PostgreSQL 16.

We continue to follow the news of the upcoming PostgreSQL 16. The third CommitFest concluded in early December. Let's look at the results.
If you missed the previous CommitFests, check out our reviews: 2022-07, 2022-09.
Here are the patches I want to talk about:
meson: a new source code build system
Documentation: a new chapter on transaction processing
psql: \d+ indicates foreign partitions in a partitioned table
psql: extended query protocol support
Predicate locks on materialized views
Tracking last scan time of indexes and tables
pg_buffercache: a new function pg_buffercache_summary
walsender displays the database name in the process status
Reducing the WAL overhead of freezing tuples
Reduced power consumption when idle
postgres_fdw: batch mode for COPY
Modernizing the GUC infrastructure
Hash index build optimization
MAINTAIN ― a new privilege for table maintenance
SET ROLE: better role change management
Support for file inclusion directives in pg_hba.conf and pg_ident.conf
Regular expressions support in pg_hba.conf

It's official! PostgreSQL 15 is out, and the community is abuzz discussing all the new features of the fresh release.
Meanwhile, the October CommitFest for PostgreSQL 16 had come and gone, with its own notable additions to the code.
If you missed the July CommitFest, our previous article will get you up to speed in no time.
Here are the patches I want to talk about:
SYSTEM_USER function
Frozen pages/tuples information in autovacuum's server log
pg_stat_get_backend_idset returns the actual backend ID
Improved performance of ORDER BY / DISTINCT aggregates
Faster bulk-loading into partitioned tables
Optimized lookups in snapshots
Bidirectional logical replication
pg_auth_members: pg_auth_members: role membership granting management
pg_auth_members: role membership and privilege inheritance
pg_receivewal and pg_recvlogical can now handle SIGTERM

So far we've discussed query execution stages, statistics, and the two basic data access methods: Sequential scan and Index scan.
The next item on the list is join methods. This article will remind you what logical join types are out there, and then discuss one of three physical join methods, the Nested loop join. Additionally, we will check out the row memoization feature introduced in PostgreSQL 14.
August was a special month in PostgreSQL release cycle as the first CommitFest for the 16th PostgreSQL release was held.
Let's compile the server and check out the cool new stuff!

In the previous articles, we have covered query execution stages, statistics, sequential and index scan, and two of the three join methods: nested loop and hash join.
This last article of the series will cover the merge algorithm and sorting. I will also demonstrate how the three join methods compare against each other.

So far we have covered query execution stages, statistics, sequential and index scan, and have moved on to joins.

In previous articles we discussed query execution stages and statistics. Last time, I started on data access methods, namely Sequential scan. Today we will cover Index Scan.
In previous articles we discussed how the system plans a query execution and how it collects statistics to select the best plan. The following articles, starting with this one, will focus on what a plan actually is, what it consists of, and how it is executed.
In this article, I will demonstrate how the planner calculates execution costs. I will also discuss access methods and how they affect these costs, and use the sequential scan method as an illustration. Lastly, I will talk about parallel execution in PostgreSQL, how it works, and when to use it.
I will use several seemingly complicated math formulas later in the article. You don't have to memorize any of them to get to the bottom of how the planner works; they are merely there to show where I get my numbers from.

In the last article we reviewed the stages of query execution. Before we move on to plan node operations (data access and join methods), let's discuss the bread and butter of the cost optimizer: statistics.
Dive in to learn what types of statistics PostgreSQL collects when planning queries, and how they improve query cost assessment and execution times.
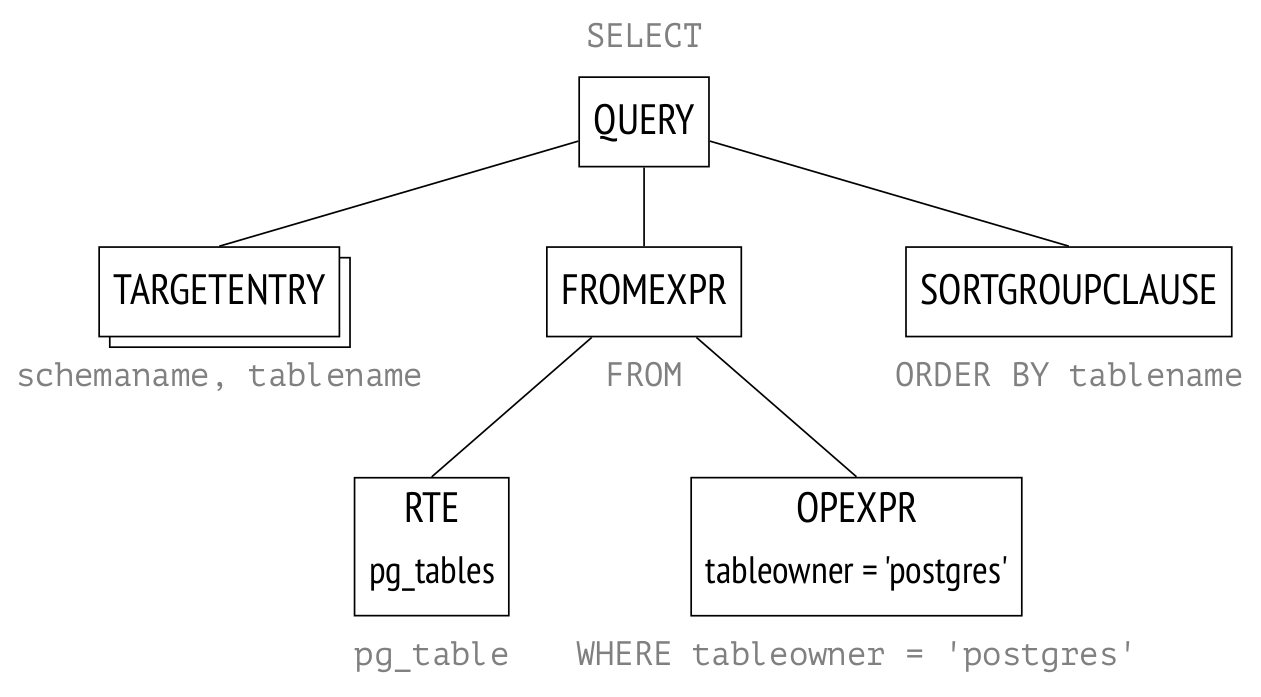
Hello! I'm kicking off another article series about the internals of PostgreSQL. This one will focus on query planning and execution mechanics.
In the first article we will split the query execution process into stages and discuss what exactly happens at each stage.



