

Программисты любят программировать. Но если вы – программист, и результат вашего творения делается не “в стол”, рано или поздно наступит момент, когда нужно показать его миру: заказчику, пользователям, инвесторам, etc. Хорошо, когда вы работаете в компании, где есть целый отдел или хотя бы отдельный специально обученный человек, который может развернуть ваше приложение где вы скажете и как вы скажете. Однако не все компании могут себе такое позволить. А уж если вы фрилансер или это ваш пет-проект, развертывание приложения точно ляжет на вас.
О чем вам нужно позаботиться перед развертыванием? Арендовать сервер, настроить его, зарегистрировать доменное имя, получить SSL-сертификат, подумать о доставке обновлений.
Чтобы предметно рассмотреть процесс развертывания, напишем небольшой API-сервис TODO-заметок на языке программирования Python с использованием микрофреймворка Flask.
Планирование
Каждая заметка будет определяться следующим образом:









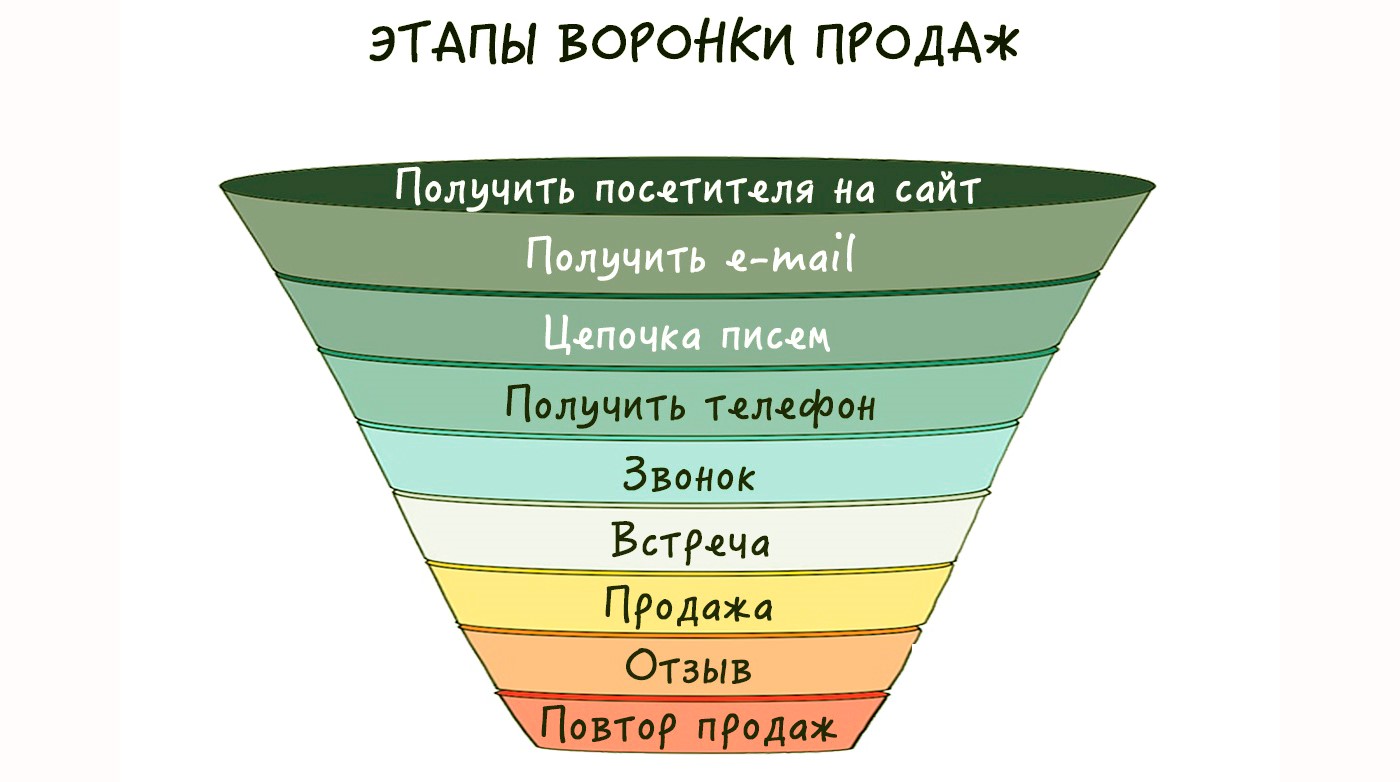




 В Акселераторе ФРИИ работу со стартапами начинают с того, что пытаются определить, на какой стадии развития находится компания. Почему именно с этого? В целом, большая часть проблем у стартапов появляются от отсутствия фокуса: предприниматели совершают много ненужных действий, не концентрируясь на том, что приведет их бизнес к точке безубыточности. Чтобы понять, какие действия компании необходимо совершить в настоящий момент, нужно определить, на каком этапе развития она находится. Для этого во ФРИИ используется такой инструмент, как дорожная карта или road map. Мы выделяем в развитии ИТ-стартапов три больших этапа – поиск и изучение клиентов, тестирование каналов продаж и масштабирование. В данном материале мы пошагово рассмотрим первую большую стадию развития стартапа – Customer Discovery, поиск и изучение клиентов. Обычно оборот компаний на этой стадии не превышает 100 тысяч рублей. Какие шаги должен совершить ИТ-стартап, чтобы уверенно перейти к следующей стадии — тестированию каналов продаж?
В Акселераторе ФРИИ работу со стартапами начинают с того, что пытаются определить, на какой стадии развития находится компания. Почему именно с этого? В целом, большая часть проблем у стартапов появляются от отсутствия фокуса: предприниматели совершают много ненужных действий, не концентрируясь на том, что приведет их бизнес к точке безубыточности. Чтобы понять, какие действия компании необходимо совершить в настоящий момент, нужно определить, на каком этапе развития она находится. Для этого во ФРИИ используется такой инструмент, как дорожная карта или road map. Мы выделяем в развитии ИТ-стартапов три больших этапа – поиск и изучение клиентов, тестирование каналов продаж и масштабирование. В данном материале мы пошагово рассмотрим первую большую стадию развития стартапа – Customer Discovery, поиск и изучение клиентов. Обычно оборот компаний на этой стадии не превышает 100 тысяч рублей. Какие шаги должен совершить ИТ-стартап, чтобы уверенно перейти к следующей стадии — тестированию каналов продаж? 