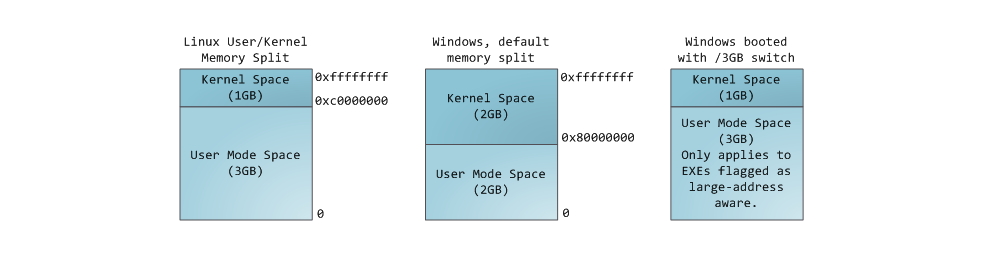
В одном проекте, связанном с безопасностью Linux-систем, нам потребовалось перехватывать вызовы важных функций внутри ядра (вроде открытия файлов и запуска процессов) для обеспечения возможности мониторинга активности в системе и превентивного блокирования деятельности подозрительных процессов.
В одном проекте, связанном с безопасностью Linux-систем, нам потребовалось перехватывать вызовы важных функций внутри ядра (вроде открытия файлов и запуска процессов) для обеспечения возможности мониторинга активности в системе и превентивного блокирования деятельности подозрительных процессов.В процессе разработки нам удалось изобрести довольно неплохой подход, позволяющий удобно перехватить любую функцию в ядре по имени и выполнить свой код вокруг её вызовов. Перехватчик можно устанавливать из загружаемого GPL-модуля, без пересборки ядра. Подход поддерживает ядра версий 3.19+ для архитектуры x86_64.
 В WinAPI есть функция
В WinAPI есть функция 



 Привет, Хабр!
Привет, Хабр! Пожалуй, начну с того, что если перегружаться 15 раз в год, то любой «тюнинг» процесса загрузки отнимает больше времени, чем будет выиграно на перезагрузках за все время жизни системы. Однако, спортивный интерес берет свое, тем более, что
Пожалуй, начну с того, что если перегружаться 15 раз в год, то любой «тюнинг» процесса загрузки отнимает больше времени, чем будет выиграно на перезагрузках за все время жизни системы. Однако, спортивный интерес берет свое, тем более, что