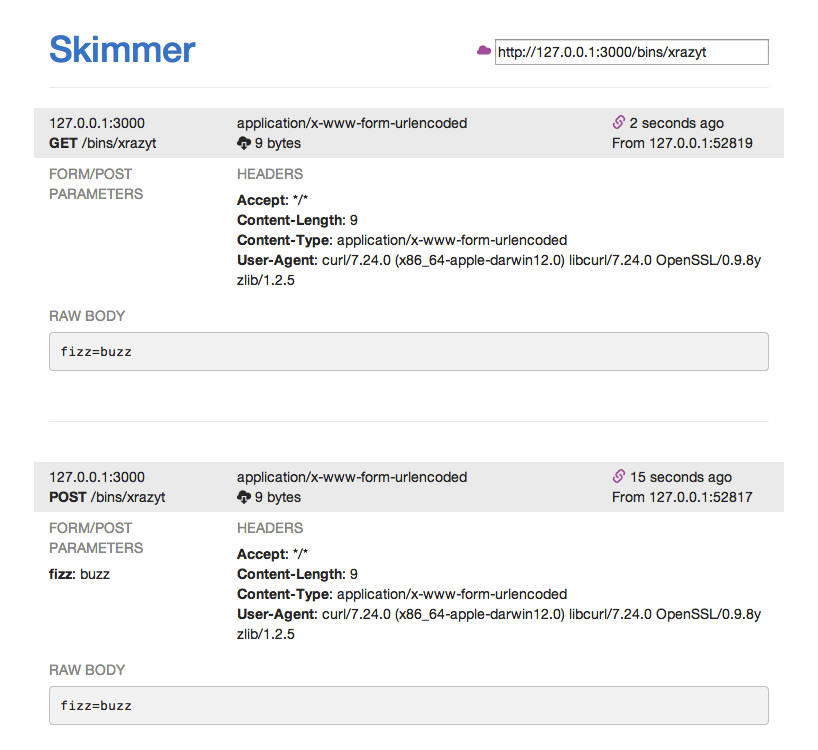
Трансдьюсеры в JavaScript. Часть вторая
7 мин
В первой части мы остановились на следующей спецификации: Трансдьюсер — это функция принимающая функцию
Функция
Чтобы получить новый текущий результат в функции
Т.е. нужно вызывать
В итоге получается, что при обработке каждого элемента, одна функция
Итак, сейчас мы можем:
step, и возвращающая новую функцию step.step⁰ → step¹
Функция
step, в свою очередь, принимает текущий результат и следующий элемент, и должна вернуть новый текущий результат. При этом тип данных текущего результата не уточняется.result⁰, item → result¹
Чтобы получить новый текущий результат в функции
step¹, нужно вызвать функцию step⁰, передав в нее старый текущий результат и новое значение, которое мы хотим добавить. Если мы не хотим добавлять значение, то просто возвращем старый результат. Если хотим добавить одно значение, то вызываем step⁰, и то что он вернет возвращаем как новый результат. Если хотим добавить несколько значений, то вызываем step⁰ несколько раз по цепочке, это проще показать на примере реализации трансдьюсера flatten:function flatten() {
return function(step) {
return function(result, item) {
for (var i = 0; i < item.length; i++) {
result = step(result, item[i]);
}
return result;
}
}
}
var flattenT = flatten();
_.reduce([[1, 2], [], [3]], flattenT(append), []); // => [1, 2, 3]
Т.е. нужно вызывать
step несколько раз, каждый раз сохраняя текущий результат в переменную, и передавая его при следующем вызове, а в конце вернуть уже окончательный.В итоге получается, что при обработке каждого элемента, одна функция
step, вызывает другую, а та следующую, и так до последней служебной функции step, которая уже сохраняет результат в коллекцию (append из первой части).Итак, сейчас мы можем:
- Изменять элементы (прим. map)
- Пропускать элементы (прим. filter)
- Выдавать для одного элемента несколько новых (прим. flatten)
 CoffeeScript поистине удивительный язык, который позволяет взглянуть на JavaScript с совершенно иной и намного более притягательной стороны. Давным давно, когда я только начинал заниматься фронт-эндом — меня буквально силками заставляли писать именно на нём (корпоративный стандарт), сейчас же я не могу писать на языке оригинала.
CoffeeScript поистине удивительный язык, который позволяет взглянуть на JavaScript с совершенно иной и намного более притягательной стороны. Давным давно, когда я только начинал заниматься фронт-эндом — меня буквально силками заставляли писать именно на нём (корпоративный стандарт), сейчас же я не могу писать на языке оригинала.


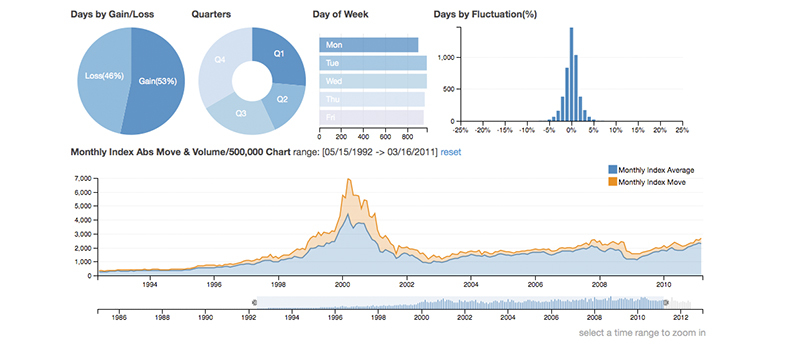

 Привет, друзья.
Привет, друзья. Частенько читаю Хабр и заметил что в последнее время появились Дайджесты новостей по многим тематикам, таким как веб-разработка на php, разработка на Python, мобильные приложения, но не встретил ни одного подборки по популярному сейчас направлению, а именно анализу данных и big data.
Частенько читаю Хабр и заметил что в последнее время появились Дайджесты новостей по многим тематикам, таким как веб-разработка на php, разработка на Python, мобильные приложения, но не встретил ни одного подборки по популярному сейчас направлению, а именно анализу данных и big data. 

 Изначально хотел назвать статью «HTML по ГОСТ`у», но потом выяснилось что у большинства программистов не было предмета «Метрология и стандартизация» и о «стандартизации», «сертификации», «унификации» не все слышали.
Изначально хотел назвать статью «HTML по ГОСТ`у», но потом выяснилось что у большинства программистов не было предмета «Метрология и стандартизация» и о «стандартизации», «сертификации», «унификации» не все слышали.