С момента появления домашних компьютеров существует возможность расширять их функционал путём установки большего количества RAM, более ёмких накопителей, дополнительных комплектующих. Но только с появлением IBM PC привычной стала идея о полностью открытой модульной компьютерной системе. А именно, концепция карт расширения позволила пользователям компьютеров не зависеть от конфигураций систем, предлагаемых производителями. Подобные конфигурации можно было, в ограниченных пределах, расширять комплектующими, рассчитанными исключительно на эти системы. Благодаря универсальным картам расширения появились целые отрасли промышленности, они стали и причиной возникновения большого рынка любительских устройств, которые можно было подключать к компьютерам.

В первом IBM PC было пять 8-битных слотов расширения, подключённых прямо к процессору 8088. Компьютер IBM PC/AT был основан на процессоре 80286, в результате слоты стали 16-битными. С помощью слотов расширения к компьютеру можно было подключать практически всё что угодно: графические и сетевые карты, дополнительную память, какие-то особые платы. Хотя для этих слотов расширения и не существовало официального наименования, во времена PC/AT их называли, соответственно, PC-шинами и AT-шинами. А название Industry Standard Architecture (ISA) — это ретроним, который придумали создатели клонов PC.
Такая открытость ISA означала то, что можно было достаточно легко и дёшево создавать собственные ISA-карты. То же касалось и шины PCI, которая появилась после ISA и была такой же открытой. В результате до сих пор существует полная жизни экосистема, в которой есть место и любительским звуковым картам, рассчитанным на слоты PCI или ISA, и картам расширения, позволяющим оснастить IBM PC 1981-го года поддержкой USB, и много чему ещё.
С чего начать тому, кто в наши дни хочет заняться работой с ISA- и PCI-картами?
В первом IBM PC было пять 8-битных слотов расширения, подключённых прямо к процессору 8088. Компьютер IBM PC/AT был основан на процессоре 80286, в результате слоты стали 16-битными. С помощью слотов расширения к компьютеру можно было подключать практически всё что угодно: графические и сетевые карты, дополнительную память, какие-то особые платы. Хотя для этих слотов расширения и не существовало официального наименования, во времена PC/AT их называли, соответственно, PC-шинами и AT-шинами. А название Industry Standard Architecture (ISA) — это ретроним, который придумали создатели клонов PC.
Такая открытость ISA означала то, что можно было достаточно легко и дёшево создавать собственные ISA-карты. То же касалось и шины PCI, которая появилась после ISA и была такой же открытой. В результате до сих пор существует полная жизни экосистема, в которой есть место и любительским звуковым картам, рассчитанным на слоты PCI или ISA, и картам расширения, позволяющим оснастить IBM PC 1981-го года поддержкой USB, и много чему ещё.
С чего начать тому, кто в наши дни хочет заняться работой с ISA- и PCI-картами?




 После трёх лет работы со студийным светом я думал, что знаю про накамерную вспышку если не всё, то очень много. Три недели назад я попал в гости к одному особо опытному стробисту, который рассказал и показал столько, что я сразу понял, что надо садиться и делать перепись грабель, а потом тестить, тестить и ещё раз тестить.
После трёх лет работы со студийным светом я думал, что знаю про накамерную вспышку если не всё, то очень много. Три недели назад я попал в гости к одному особо опытному стробисту, который рассказал и показал столько, что я сразу понял, что надо садиться и делать перепись грабель, а потом тестить, тестить и ещё раз тестить. 
 Знаете, люблю я книжки про всякие интересные алгоритмы, и вот недавно попалась еще одна такая книжка.
Знаете, люблю я книжки про всякие интересные алгоритмы, и вот недавно попалась еще одна такая книжка. 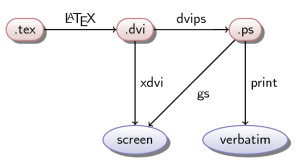 Многие достаточно часто сталкиваются с необходимостью создания различных диаграмм, графов, деревьев для удобного представления информации. Особенно важным этот вопрос может оказаться при создании презентаций. Большинство офисных пакетов предоставляют возможность создавать красивые диаграммы при помощи интерактивного интерфейса. А если нужно создать большую диаграмму? Или записать в ней математические формулы? Сосредоточиться на содержании, а не оформлении и расположении элементов на экране?
Многие достаточно часто сталкиваются с необходимостью создания различных диаграмм, графов, деревьев для удобного представления информации. Особенно важным этот вопрос может оказаться при создании презентаций. Большинство офисных пакетов предоставляют возможность создавать красивые диаграммы при помощи интерактивного интерфейса. А если нужно создать большую диаграмму? Или записать в ней математические формулы? Сосредоточиться на содержании, а не оформлении и расположении элементов на экране?  Проблемы контроля версий баз данных и миграций между версиями уже не раз поднимались как на Хабре (
Проблемы контроля версий баз данных и миграций между версиями уже не раз поднимались как на Хабре (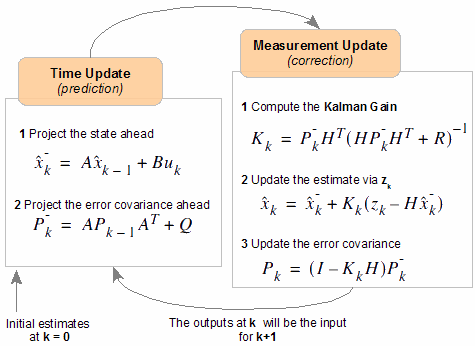 Недавно прочитал пост из «Дополненной реальности», в котором упоминается Фильтр Калмана в сравнении с более простым «альфа-бета» фильтром. Давно собирался сочинить нечто вроде сниппета по составлению ФК, и вот думаю самое время. В статье я вам расскажу как на практике можно составить расширенный ФК не особо утруждая себя высоконаучными размышлениями и глубокими теоретическими изысканиями.
Недавно прочитал пост из «Дополненной реальности», в котором упоминается Фильтр Калмана в сравнении с более простым «альфа-бета» фильтром. Давно собирался сочинить нечто вроде сниппета по составлению ФК, и вот думаю самое время. В статье я вам расскажу как на практике можно составить расширенный ФК не особо утруждая себя высоконаучными размышлениями и глубокими теоретическими изысканиями.