А также:
- Бесплатные SMS
- Микроблоггинг
- Поддержка нескольких учетных записей


User
 Все мы пользуемся динамически-компонуемыми билиотеками. Их возможности поистине великолепны. Во-первых, такая библиотека загружается в физическое адресное пространство только один раз для всех процессов. Во-вторых, можно расширять функционал своей программы, подгружая дополнительную библиотеку, которая и будет этот функционал обеспечивать. И все это без перезапуска самой программы. А еще решается проблема обновлений. Для динамически компонуемой библиотеки можно определить стандартный интерфейс и влиять на функционал и качество своей основной программы, просто меняя версию библиотеки. Такие методы повторного использования кода даже получили название «архитектура plug-in’ов». Но топик не об этом.
Все мы пользуемся динамически-компонуемыми билиотеками. Их возможности поистине великолепны. Во-первых, такая библиотека загружается в физическое адресное пространство только один раз для всех процессов. Во-вторых, можно расширять функционал своей программы, подгружая дополнительную библиотеку, которая и будет этот функционал обеспечивать. И все это без перезапуска самой программы. А еще решается проблема обновлений. Для динамически компонуемой библиотеки можно определить стандартный интерфейс и влиять на функционал и качество своей основной программы, просто меняя версию библиотеки. Такие методы повторного использования кода даже получили название «архитектура plug-in’ов». Но топик не об этом.

habrahabr.ru -> thematicmedia.ru, apple.ru, microsoft.com, ubuntu.com, yandex.ru
thematicmedia.ru -> habrahabr.ru, autokadabra.ru
autokadabra.ru -> habrahabr.ru, yandex.ru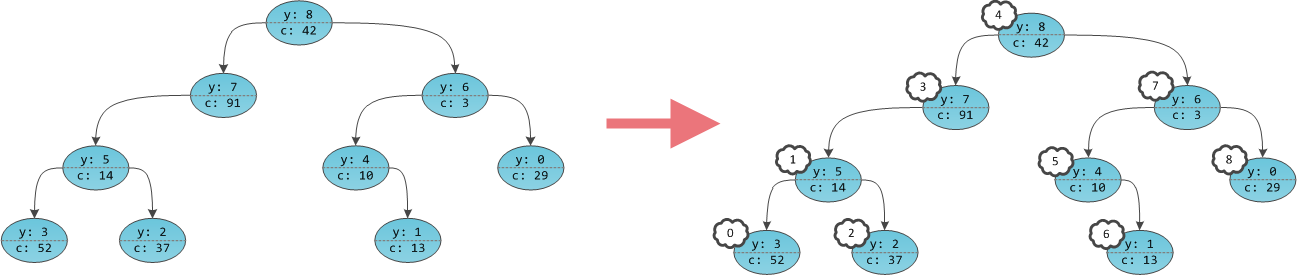
c. Игреки нужны только для балансировки, это внутренние детали структуры данных, ненужные пользователю. Иксов на самом деле нет в принципе, их хранить не нужно.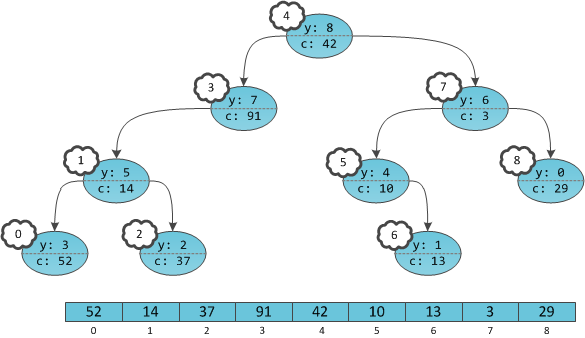


0. Зачем вообще что-то оптимизировать? 1. Оптимизация ОС (FreeBSD) 1.1 Переход на 7.х 1.2 Переход на 7.2 1.3 Переход на amd64 1.4 Разгрузка сетевой подсистемы 1.5 FreeBSD и большое кол-во файлов 1.6 Softupdates, gjournal и mount options 2. Оптимизация фронтенда (nginx) 2.1 Accept Filters 2.2 Кеширование 2.3 AIO 3. Оптимизация бэкенда 3.1 APC 3.1.1 APC locking 3.1.2 APC hints 3.1.3 APC fragmentation 3.2 PHP 5.3 4. Оптимизация базы данных 4.1 MySQL 4.1.1 Переход на 5.1 4.1.2 Переход на InnoDB 4.1.3 Встроеный кеш MySQL - Query Cache 4.1.4 Индексы 4.2 PostgreSQL 4.2.1 Индексы 4.2.2 pgBouncer и другие. 4.2.3 pgFouine 4.3 Разгрузка базы данных 4.3.1 SphinxQL 4.3.2 Не-RDBMS хранилище 4.4 Кодировки 4.5 Асинхронность Приложение. Мелочи. 1. SSHGuard или альтернатива. 2. xtrabackup 3. Перенос почты на другой хост 4. Интеграция со сторонним ПО 5. Мониторинг 6. Минусы оптимизации
+-------------------+ ------------------ | Сервер обработки | | | <===WAIT=== Клиент A | и базы данных | ======IN=======> | Мультиплексор | <===WAIT=== Клиент B | (e.g Apache + PHP | | | <===WAIT=== Клиент C +-------------------+ ------------------ (указаны направления установления TCP-соединений).