Фото взято из публикации
Введение
Одна из наиболее актуальных задач цифровой обработки сигналов – задача очистки сигнала от шума. Любой практический сигнал содержит не только полезную информацию, но и следы некоторых посторонних воздействий помехи или шума. Кроме этого, при вибродиагностике сигналы от вибродатчиков имеют не стационарный частотный спектр, что усложняет задачу фильтрации.
Существует множество различных способов удаления высокочастотного шума из сигнала. Например, библиотека Scipy содержит фильтры, основанные на различных методах фильтрации: Калмана; сглаживание сигнала путём его усреднения по оси времени, и другие.
Однако, преимущество метода дискретного вейвлет преобразования (DWT) состоит в многообразии форм вейвлет. Можно выбрать вейвлет, который будет иметь форму, характерную для ожидаемых явлений. Например, можно выделить сигнал в заданном частотном диапазоне, форма которого отвечает за появление дефекта.
Целью настоящей публикации является анализ методов фильтрации сигналов вибродатчиков с применением DWT преобразования сигнала, фильтра Калмана и метода скользящего среднего.
Исходные данные для анализа
В публикации работу фильтров основанных на различных методах фильтрации будем анализировать используя
набор данных НАСА. Данные получены на экспериментальной платформе PRONOSTIA:

Набор содержит данные о сигналах вибродатчиков по износу подшипников различных типов. Назначение папок с файлами сигналов приведено в
таблице:
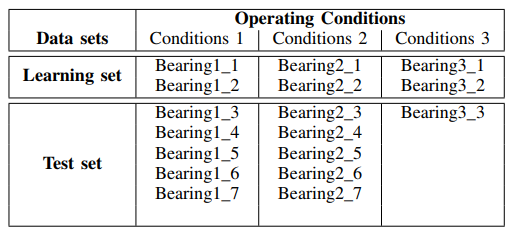
Мониторинг состояния подшипников обеспечивается сигналами датчиков вибрации (горизонтальным и вертикальным акселерометрами), силы и температуры.

Сигналы получены для трёх различных нагрузок:
- Первые рабочие условия: 1800 об / мин и 4000 Н;
- Вторые рабочие условия: 1650 об / мин и 4200 Н;
- Третьи рабочие условия: 1500 об / мин и 5000 Н.












 Aarch64 — это 64-битная архитектура от ARM (иногда её называют arm64). В этой статье я расскажу, чем она отличается от "обычных" (32-битных) ARM и насколько сложно портировать на него свою систему.
Aarch64 — это 64-битная архитектура от ARM (иногда её называют arm64). В этой статье я расскажу, чем она отличается от "обычных" (32-битных) ARM и насколько сложно портировать на него свою систему. 