
Всем привет. Меня зовут Борис, уже несколько лет я увлекаюсь теорией обучения и запоминания — тем, как работает мозг с новой информацией. Сегодня я поделюсь своим способом читать книги.
Возможно вы слышали про алгоритм чтения книг, который позволяет сохранить в голове максимум информации. Про него мне рассказал тренер по скорочтению, а позднее я увидел этот алгоритм у Бюзана в книге «Супермышление».
Алгоритм для обычных книг
Всё очень просто:
- Читаем автора и название;
- Задаем вопросы, ответы на которые мы хотим найти в книге;
- Пролистываем: разглядываем картинки, цитаты;
- Читаем содержание, оглавление, аннотации;
- Читаем книгу (чем быстрее, тем лучше);
- Выделяем основную тему;
- Выделяем факты и новизну;
- Пролистываем книгу;
- Опционально: записываем в табличку в экселе, о чем книга, кто ее посоветовал, стоит ли перечитывать и почему.
Если через полгода нужно будет вспомнить, что было в той книге, ее можно будет просто пролистать — этого будет достаточно. Работает отлично с книгами по психологии, переговорам, маркетингу, etc.
Увы, читать таким способом книгу Дэвида Флэнэгэна «JavaScript. Подробное руководство, 6-е издание» или ng-book бессмысленно и бесполезно. В голове не останется ничего, а время потеряется. И вообще, техника скорочтения для подобных книг скорее вредна, чем полезна.
 В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров. 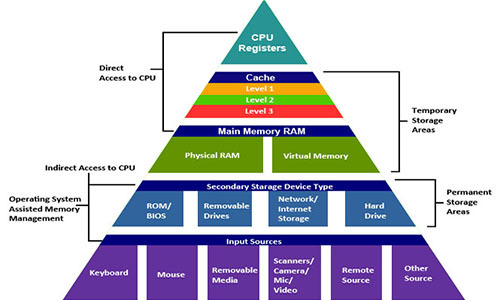







 abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.
abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.
 Вы наверняка слышали, что недавно вышел новый релиз IaaS-платформы OpenStack —
Вы наверняка слышали, что недавно вышел новый релиз IaaS-платформы OpenStack —