
У того, кто в детстве не писал на Прологе — нет сердца, а у того, кто пишет на нём сегодня — нет мозгов. (оригинал)
Если вас всегда терзали мучительные сомнения — что за фигня это Логическое Программирование (ЛП) и вообще зачем оно нужно? То это статья для вас.
Можно по-разному разделить языки программирования на группы (часто их называют парадигмами программирования), например, вот так:
- структурное: программа разбивается на блоки — подпрограммы (изолированные друг от друга), а основными элементами управления являются последовательность команд, ветвление и цикл.
- объектно-ориентированное: задача моделируется в виде объектов, которые отправляют друг другу сообщения. Объекты обладают свойствами и методами. Абстракция. Инкапсуляция. Полиморфизм. Ну в общем, все в курсе.
- функциональное: базовым элементом является функция и сама задача моделируется в виде функции, а, точнее, чаще всего в виде их композиции, если f(.) и g(.) — это функции, то f(g(.)) — это их композиция.
- логическое: вот тут, как правило, начинается феерия — если про первые три написаны сотни статей, книг, обзоров, презентаций и учебников, то здесь мы в лучшем случае видим что-то про Prolog и разработки времён Pink Floyd и Procol Harum (ну хоть с музыкой им тогда повезло) и на этом история заканчивается.
Вот эту оплошность я и собираюсь сегодня исправить.
Важнейший тезис этой статьи:
Логическое программирование != Prolog.
И вообще последний вам скорее всего не нужен. А вот первое вполне может быть.
Структура статьи:
- Что такое Пролог и почему он вам скорее всего не нужен
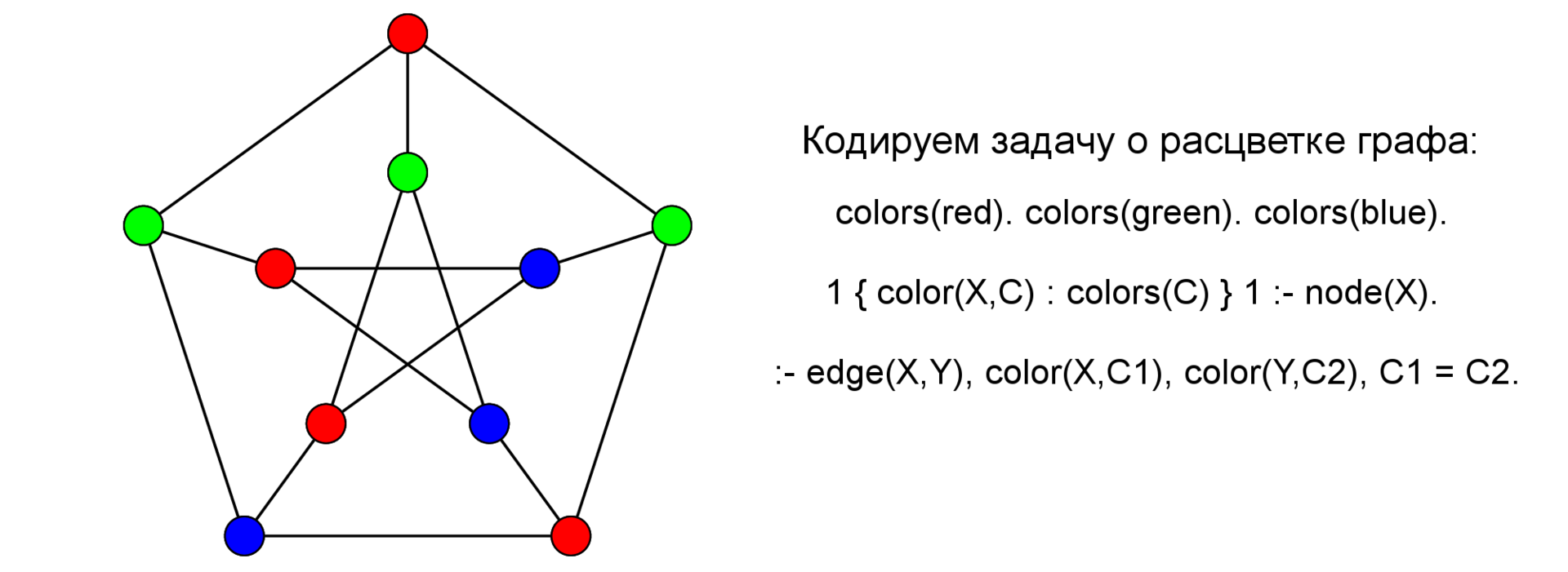
- Зачем оно надо, или краткое введение в Answer Set Programming
- Решаем задачи на ASP
- Комбинаторная оптимизация
- Вероятностное ЛП: ProbLog
- ЛП на классической логике FO(.) и IDP
- Sketched Answer Set Programming
- Экспериментальный анализ
- Тестирование и корректность программ
- Заключение









 "
"





