Разбирая старые бумаги наткнулся на изрядно потрёпанную тетрадь, в которой обнаружил наброски алгоритма поиска покрытия. Автор алгоритма Виктор Анатольевич Щербанов — мой учитель, под руководством которого я работал в девяностые годы прошлого столетия. Моё скромное участие в основном заключалось в том, что я предлагал в большинстве случаев неверные (а порой и просто бредовые) варианты. Что в общем-то не помешало Шефу (так мы его называли между собой) таки довести работу над алгоритмом до логического завершения. Где-то в двухтысячных годах алгоритм был опубликован в одном из институтских изданий Томска. Но думаю, что не лишним будет вспомнить его ещё раз. Собственно в память о Шефе я и решил написать этот пост. Может быть алгоритм покажется кому-то интересным или подтолкнёт на какие-то новые идеи по реализации алгоритма.

Вова @vvsh
User
Самая полная фотография видимой Вселенной от Hubble
1 min

NASA и ESA на днях выложили в открытый доступ интереснейшую фотографию видимой части Вселенной. Исходником является Hubble Ultra Deep Field. На этой фотографии можно насчитать (если хватит терпения и зрения) 10 тысяч галактик и еще сколько-то там отдельных светил. Стоит отметить, что на фото вы можете видеть множество точек разных цветов. Это тоже галактики. Выложено также и видео, с демонстрацией того участка пространства, о котором идет речь.
Отличием этой фотографии от всех прочих является, во-первых, добавление ультрафиолетового спектра (т.е. создатели фотографии сделали на фотографии видимым УФ-излучение). Благодаря этому на фото появилось огромное количество объектов, излучающих только в УФ-спектре.
Анализ неявных предпочтений пользователей. Научно-технический семинар в Яндексе
9 min
Анализ неявных предпочтений пользователей, выраженных в переходах по ссылкам и длительности просмотра страниц, — важнейший фактор в ранжировании документов в результатах поиска или, например, показе рекламы и рекомендации новостей. Алгоритмы анализа кликов хорошо изучены. Но можно ли узнать что-то ещё об индивидуальных предпочтениях человека, используя больше информации о его поведении на сайте? Оказывается, траектория движения мыши позволяет узнать, какие фрагменты просматриваемого документа заинтересовали пользователя.
Этому вопросу и было посвящено исследование, проведенное мной, Михаилом Агеевым, совместно с Дмитрием Лагуном и Евгением Агиштейном в Emory Intelligent Information Access Lab Университета Эмори.
Мы изучали методы сбора данных и алгоритмы анализа поведения пользователя по движениям мыши, а также возможности применения этих методов на практике. Они позволяют существенно улучшить формирование сниппетов (аннотаций) документов в результатах поиска. Работа с описанием этих алгоритмов была отмечена дипломом «Best Paper Shortlisted Nominee» на международной конференции ACM SIGIR в 2013 году. Позже я представил доклад о результатах проделанной работы в рамках научно-технических семинаров в Яндексе. Его конспект вы найдете под катом.
Этому вопросу и было посвящено исследование, проведенное мной, Михаилом Агеевым, совместно с Дмитрием Лагуном и Евгением Агиштейном в Emory Intelligent Information Access Lab Университета Эмори.
Мы изучали методы сбора данных и алгоритмы анализа поведения пользователя по движениям мыши, а также возможности применения этих методов на практике. Они позволяют существенно улучшить формирование сниппетов (аннотаций) документов в результатах поиска. Работа с описанием этих алгоритмов была отмечена дипломом «Best Paper Shortlisted Nominee» на международной конференции ACM SIGIR в 2013 году. Позже я представил доклад о результатах проделанной работы в рамках научно-технических семинаров в Яндексе. Его конспект вы найдете под катом.
Умный дом — общая архитектура системы
2 min
Когда я наконец решил рассказать хабру о моем умном доме — он был уже готов, и я не знал как рассказать так много, а самое главное — с чего начать. В предыдущем посте рассказывал о комнатных контроллерах, но, без общего представления какую роль эта штука играет в доме и зачем оно вообще надо — все это кажется, мягко говоря, оторванным от контекста.
Лучше поздно, чем никогда. Я наконец понял свою ошибку, и теперь начну с того, с чего обычно начинаются все книги — с оглавления.
Структурное представление умного дома:
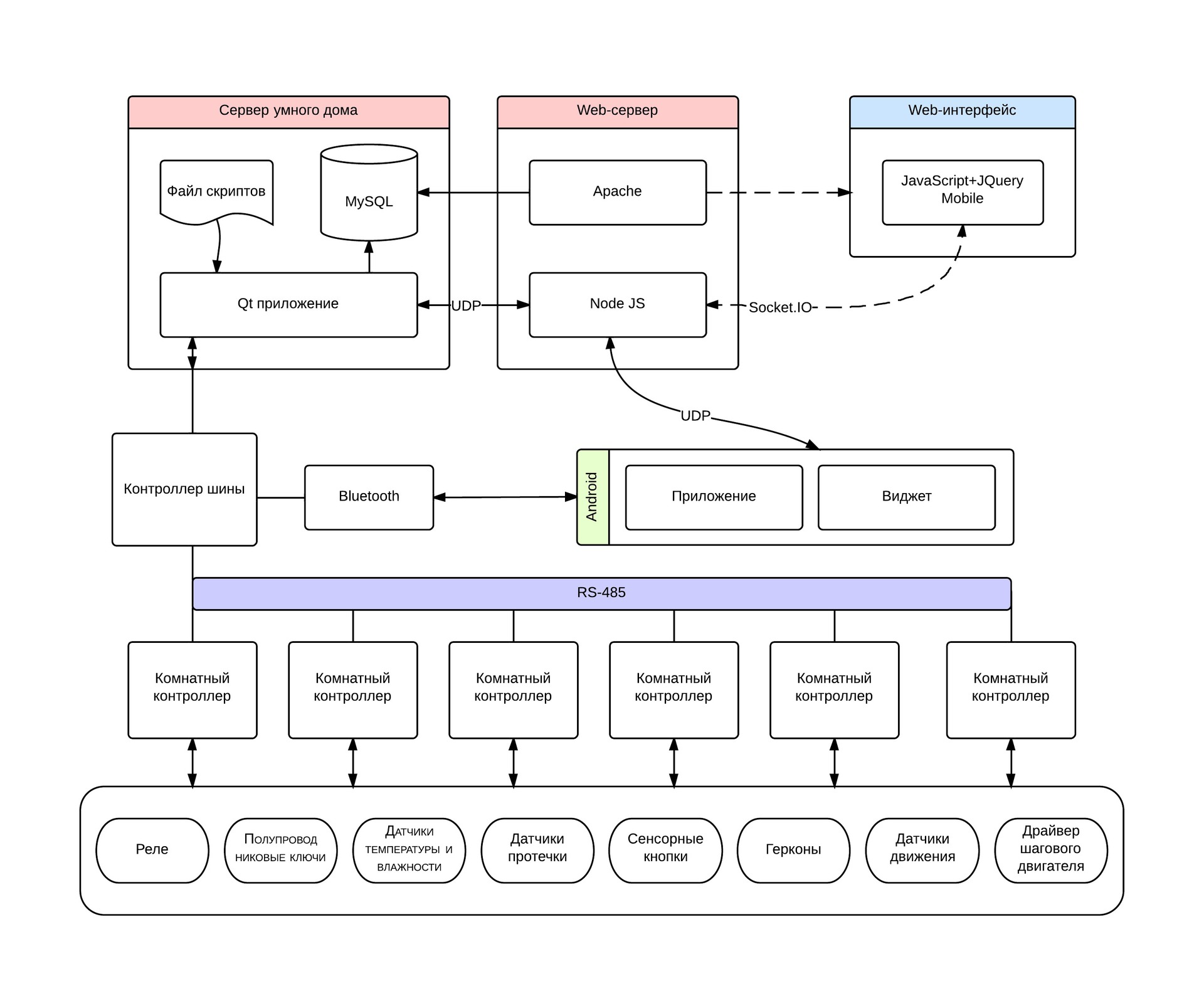
Лучше поздно, чем никогда. Я наконец понял свою ошибку, и теперь начну с того, с чего обычно начинаются все книги — с оглавления.
Структурное представление умного дома:
Основные принципы настройки Garbage Collection с нуля
7 min
В данной статье я бы не хотел заострять внимание на принципе работы сборщика мусора — об этом прекрасно и наглядно описано здесь: habrahabr.ru/post/112676. Хочется больше перейти к практическим основам и количественным характеристикам по настройке Garbage Collection в JVM — и попытаться понять насколько это может быть эффективным.
Рассмотрим следующие показатели:
Как правило, перечисленные характеристики являются компромиссными и улучшение одной из них ведёт к затратам по остальным. Для большинства приложений важны все три характеристики, но зачастую одна или две имеют большее значение для приложения — это и будет отправной точкой в настройке.
Количественные характеристики оценки эффективности GC
Рассмотрим следующие показатели:
- Пропускная способность Мера, определяющая способность приложения работать в пиковой нагрузке не зависимо от пауз во время сборки и размера необходимой памяти
- Время отклика Мера GC, определяющая способность приложения справляться с числом остановок и флуктуаций работы GC
- Размер используемой памяти Размер памяти, который необходим для эффективной работы GC
Как правило, перечисленные характеристики являются компромиссными и улучшение одной из них ведёт к затратам по остальным. Для большинства приложений важны все три характеристики, но зачастую одна или две имеют большее значение для приложения — это и будет отправной точкой в настройке.
Автоматическая расстановка поисковых тегов
6 min
В этой статье мы попытаемся рассказать о проблеме множественной классификации на примере решения задачи автоматической расстановки поисковых тегов для текстовых документов в нашем проекте www.favoraim.com. Хорошо знакомые с предметом читатели скорее всего не найдут для себя ничего нового, однако в процессе решения этой задачи мы перечитали много различной литературы где о проблеме множественной классификации говорилось очень мало, либо не говорилось вообще.
Итак, начнем с постановки задачи классификации. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. Существует неизвестная целевая зависимость — отображение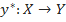 , значения которой известны только на объектах конечной обучающей выборки
, значения которой известны только на объектах конечной обучающей выборки 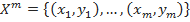 . Требуется построить алгоритм
. Требуется построить алгоритм 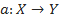 , способный классифицировать произвольный объект x∈X. Однако более распространенным является вероятностная постановка задачи. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. На множестве пар «объект, класс» X×Y определена вероятностная мера P. Имеется конечная обучающая выборка независимых наблюдений , полученных согласно вероятностной мере P.
, способный классифицировать произвольный объект x∈X. Однако более распространенным является вероятностная постановка задачи. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. На множестве пар «объект, класс» X×Y определена вероятностная мера P. Имеется конечная обучающая выборка независимых наблюдений , полученных согласно вероятностной мере P.
Итак, начнем с постановки задачи классификации. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. Существует неизвестная целевая зависимость — отображение
, значения которой известны только на объектах конечной обучающей выборки . Требуется построить алгоритм , способный классифицировать произвольный объект x∈X. Однако более распространенным является вероятностная постановка задачи. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. На множестве пар «объект, класс» X×Y определена вероятностная мера P. Имеется конечная обучающая выборка независимых наблюдений , полученных согласно вероятностной мере P.Отладка Java приложения, когда оно совсем не ждёт — добро пожаловать в InTrace подход
6 min
Tutorial
Доводилось ли вам когда-либо исследовать шаг за шагом выполние некого Java кода, который не удосужились снабдить средствами логирования или прочими механизмами наблюдения?
Усложним задачу тем, что не будем перекомпилировать исследуемый код, да и вообще перезапускать существующий процесс (тот случай, когда непонятное поведение было да и при перестарте сплыло). Java машина, конечно же, запущена с самыми обыкновенными опциями (без параметров для аттача дебагера или ещё каких наворотов).
А так хочется понять, что же происходит.
Именно этим мы и займёмся.
Усложним задачу тем, что не будем перекомпилировать исследуемый код, да и вообще перезапускать существующий процесс (тот случай, когда непонятное поведение было да и при перестарте сплыло). Java машина, конечно же, запущена с самыми обыкновенными опциями (без параметров для аттача дебагера или ещё каких наворотов).
А так хочется понять, что же происходит.
Именно этим мы и займёмся.
Аннотации в Java, часть I
5 min
Это первая часть статьи, посвященной такому языковому механизму Java 5+ как аннотации. Она имеет вводный характер и рассчитана на Junior разработчиков или тех, кто только приступает к изучению языка.
Я занимаюсь онлайн обучением Java и опубликую часть учебных материалов в рамках переработки курса Java Core.
Также я веду курс «Scala for Java Developers» на платформе для онлайн-образования udemy.com (аналог Coursera/EdX).
Мой метод обучения состоит в том, что я
Данная статье следует пунктам #1 (последовательность примеров) и #2(варианты применения).
Я занимаюсь онлайн обучением Java и опубликую часть учебных материалов в рамках переработки курса Java Core.
Также я веду курс «Scala for Java Developers» на платформе для онлайн-образования udemy.com (аналог Coursera/EdX).
Мой метод обучения состоит в том, что я
- строю усложняющуюся последовательность примеров
- объясняю возможные варианты применения
- объясняю логику двигавшую авторами (по мере возможности)
- даю большое количество тестов (50-100) всесторонне проверяющее понимание и демонстрирующих различные комбинации
- даю лабораторные для самостоятельной работы
Данная статье следует пунктам #1 (последовательность примеров) и #2(варианты применения).
Gremlins.js — monkey testing библиотека для веб приложений
6 min
Tutorial
Translation
Это первая из двух статей, рассказывающая о тестировании с помощью gremlins.js и grunt-gremlins. Первая статья — перевод официальной документации gremlins.js. Вторая — опыт внедрения gremlins.js в реальный проект при помощи grunt-gremlins.
Gremlins.js это monkey testing библиотека написанная на JavaScript, для Node.js и браузеров. С ее помощью проверяется надежность веб-приложений под полчищем гремлинов.
Kate: What are they, Billy?
Billy Peltzer: They're gremlins, Kate, just like Mr. Futterman said.

Графы — sigmajs
2 min
Привет, уважаемое Хабра сообщество. В один из прекрасных летних дней, позвонил мне мой товарищ, и сказал, что у него есть для меня очень интересная задача. Я люблю интересные задачи. Приехав на следующий день в офис, мы обсудили задачу. Задача, в двух словах, поставлена была следующая: отобразить на браузерном канвасе иерархию ~ 30000 пользователей с зависимостью между ними, плюс должна присутствовать некая анимация, которая в контексте данного поста не существенна, может в будущих, если на то будет время и Ваше одобрение.
Мы ударили по рукам, я сказал, что мне нужно провести «изыскания», так как сфера (JS + Canvas), была для меня была нова, и выяснить насколько развитие браузерных технологий соответствует реалиями поставленной задачи.
Через некоторое, не долгое время, я наткнулся на замечательную библиотеку — sigmajs, на тот момент была версия 0.8.2, если мне не изменят память, которая удовлетворила почти все наши амбициозные потребности.
С тех пор, много воды утекло, появилась версия сигмы 1.0.0, я обрел новый багаж знаний в сфере JS + Canvas и веба в целом. Для тех, кого я заинтриговал, прошу под кат, где будет дан краткий обзор библиотеки — sigmajs.
Мы ударили по рукам, я сказал, что мне нужно провести «изыскания», так как сфера (JS + Canvas), была для меня была нова, и выяснить насколько развитие браузерных технологий соответствует реалиями поставленной задачи.
Через некоторое, не долгое время, я наткнулся на замечательную библиотеку — sigmajs, на тот момент была версия 0.8.2, если мне не изменят память, которая удовлетворила почти все наши амбициозные потребности.
С тех пор, много воды утекло, появилась версия сигмы 1.0.0, я обрел новый багаж знаний в сфере JS + Canvas и веба в целом. Для тех, кого я заинтриговал, прошу под кат, где будет дан краткий обзор библиотеки — sigmajs.
Реализация алгоритма SSSP на GPU
8 min
Аннотация
В данной статье хочу рассказать как можно эффективно распараллелить алгоритм SSSP — поиска кратчайшего пути в графе с использованием графических ускорителей. В качестве графического ускорителя будет рассмотрена карта GTX Titan архитектуры Kepler.
Введение
В последнее время все большую роль играют графические ускорители (GPU) в не графических вычислениях. Потребность их использования обусловлена их относительно высокой производительностью и более низкой стоимостью. Как известно, на GPU хорошо решаются задачи на структурных сетках, где параллелизм так или иначе легко выделяется. Но есть задачи, которые требуют больших мощностей и используют неструктурные сетки. Примером такой задачи является Single Shortest Source Path problem (SSSP) – задача поиска кратчайших путей от заданной вершины до всех остальных во взвешенном графе. Для решения данной задачи на CPU существует, по крайней мере, два известных алгоритма: алгоритм Дейсктры и алгоритм Форда-Беллмана. Так же существуют параллельные реализации алгоритма Дейстры и Форда-Беллмана на GPU. Вот основные статьи, в которых описаны решения данной задачи:
Box2d: анатомия коллизий
10 min
Tutorial
Translation
Что такое коллизии?
В Box2D принято считать, что друг с другом сталкиваются тела, однако на самом деле при расчете коллизий используются фикстуры (fixtures, переводы слова существуют, но я не уверен, есть ли среди них устоявшийся). Объекты могут сталкиваться разными способами, поэтому библиотека предоставляет большое количество уточняющей информации, которая может быть использована в игровой логике. Например, вы можете захотеть узнать следующее:
- Когда столкновение начинается и заканчивается
- Точку соприкосновения фикстур
- Вектор нормали к линии контакта фикстур
- Какая энергия была приложена и результат коллизии
Обычно столкновение происходит очень быстро, однако в этой статье мы попытаемся взять одну конкретную коллизию и замедлить ее, чтобы успеть рассмотреть детали происходящего и информацию, которую можно извлечь из события.
Анализ современных технологий виртуализации
8 min

В настоящее время все большую популярность набирают технологии виртуализации. И это не случайно – вычислительные мощности компьютеров растут. В результате развития технологий, появляются шести-, восьми-, шестнадцатиядерные процессоры (и это еще не предел). Растет пропускная способность интерфейсов компьютеров, а также емкость и отзывчивость систем хранения данных. В результате возникает такая ситуация, что имея такие мощности на одном физическом сервере, можно перенести в виртуальную среду все серверы, функционирующие в организации (на предприятии). Это возможно сделать с помощью современной технологии виртуализации.
Технологии виртуализации в настоящее время становятся одним из ключевых компонентов современной ИТ-инфраструктуры крупных предприятий (организаций). Сейчас уже сложно представить построение нового серверного узла компании без использования технологии виртуализации. Определяющими факторами такой популярности, несмотря на некоторые недостатки, можно назвать экономию денег и времени, а также высокий уровень безопасности и обеспечение непрерывности бизнес-процессов.
В данной статье приведен анализ современной технологии виртуализации, ее преимуществ и недостатков. Также рассмотрены современные системы виртуализации и подходы к созданию виртуальных сред.
F.A.Q. по Java-конференции JPoint 2014
2 min
Эпиграф
Конференция JPoint — реальный явский хардкор, по локоть в кровище.
Дима Завалишин, http://dz.livejournal.com/878711.html
Что? Где? Когда?
В пятницу, 18 апреля, в Москве пройдёт Java-конференция JPoint для Middle/Senior-разработчиков. В программе — доклады от ведущих специалистов, представляющих компании Oracle, Одноклассники, Deutsche Bank, JetBrains, Devexperts и др.
Twister теперь действительно работает на Windows
4 min
Совсем недавно был пост о выходе Twister для Windows, к сожалению, версия обладала ошибкой, из-за которой некоторые клиенты не могли подключится, теперь всё работает.
Кроме того, теперь в твистере отображаются популярные хештеги (Trending).
Желающие протестировать P2P сервис микроблогига предлагаю попробовать снова запустить Twister (загрузив новую версию), теперь он действительно работает на Windows.
Коротко, что такое Twister — это децентрализованный аналог твиттера (микроблогинговый сервис) который построен по принципу P2P и использует всё самое лучшее от Bittorrent и Bitcoin. Другими словами — это микроблогинговый сервис который невозможно цензурировать, модерировать и у него нет единой точки отказа.
Как надо хешировать пароли и как не надо
4 min
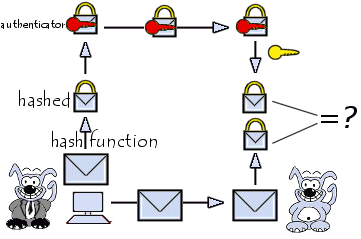
В очередной раз, когда мы заканчивали проводить аудит информационной безопасности веб-проекта, моя личная бочка с гневом переполнилась негодованием так, что оно перелилось через край в этот пост.
Постараюсь очень лаконично и быстро обрисовать ситуацию с хэшами.
Сразу определю какую задачу применения хешей буду рассматривать — аутентификация пользователей. Не токены восстановления паролей, не аутентификация запросов, не что-то еще. Это также не статья про защиту канала передачи данных, так что комментарии по challenge-response и SSL неуместны!
Миграция фотографий или ещё одна очередь на MySQL
8 min
 Недавно мы писали о том, как перед нами впервые встала задача крупномасштабной миграции данных пользователей между дата-центрами и о том как мы ее решили.
Недавно мы писали о том, как перед нами впервые встала задача крупномасштабной миграции данных пользователей между дата-центрами и о том как мы ее решили. В этот раз мы подробнее остановимся на том, каким образом осуществлялась миграция фотографий пользователей и какие структуры данных использовались для ограничения создаваемой нагрузки на сервера с фотографиями.
Ежедневно пользователи Badoo загружают примерно 3 миллиона фотографий. Для их хранения мы выделили специальный кластер серверов, занимающихся также изменением размеров, наложением «водяных знаков», импортом фотографий из других социальных сетей и прочими манипуляциями с файлами.
Все машины этого кластера можно условно разделить на три группы. Первая ― это серверы, отвечающие за быструю отдачу фотографий пользователям (можно сказать, собственная реализация CDN). В контексте миграции эти серверы нам не будут интересны. Вторая группа ― это хранилища с дисками, на которых, собственно, и находятся все фотографии. И третья группа ― это серверы, предоставляющие интерфейс ко второй группе, условно назовём их фотосерверами. На них по оптоволокну смонтированы дисковые массивы хранилищ, на эти же машины происходит загрузка фотографий и здесь же работают все скрипты, выполняющие какие-либо операции с файлами.
Таким образом, для PHP-кода совершенно неважно, на каком именно диске какого хранилища находится фотография. Все, что нужно сделать, это перенести фотографии пользователя с одного фотосервера на другой и обновить эту информацию в базе данных и некоторых демонах. Здесь важно отметить, что все фотографии пользователя всегда находятся на одном фотосервере.
Краткий обзор Spring Security
7 min
Итак, дорогой хабраюзер, предлагаю тебе рассмотреть такие аспекты Spring Security как:
- Ключевые объекты контекста Spring Security.
- Процесс аутентификации в Spring Security.
- Подключение собственно самого Spring Security к проекту.
Задача о ранце и код Грея
4 min
Не так давно на Хабре была статья «Коды Грея и задачи перебора». Статья эта скорее, математическая, нежели программистская, и мне, как простому программисту, читать её было невыносимо тяжело. Но сама тема мне знакома, поэтому я решил описать её своим взглядом, а так же рассказать о том, как использовал её в решении задачи о ранце.

КДПВ: задача о ранце на живом примере
Всё началось 10 лет назад, когда я учился в девятом классе. Я случайно подслушал разговор учителя по информатике, рассказывающего задачку кому-то из старших: дан набор чисел, и ещё одно число — контрольное. Надо найти максимальную сумму чисел из набора, которая не превышала бы контрольное число.
Задача почему-то запала мне в душу. Вернувшись домой, я быстро накатал решение: наивный перебор всех возможных сумм с выбором наилучшего. Сочетания я получал, перебирая все N-разрядные двоичные числа и беря суммы тех исходных чисел, которым соответствуют единицы. Но я с огорчением обнаружил, что при количестве элементов начиная где-то с 30, программа работает очень долго. Оно и не удивительно, ведь время работы такого алгоритма — n*2n (количество сочетаний, умноженное на длину суммы).
КДПВ: задача о ранце на живом примере
Предыстория
Всё началось 10 лет назад, когда я учился в девятом классе. Я случайно подслушал разговор учителя по информатике, рассказывающего задачку кому-то из старших: дан набор чисел, и ещё одно число — контрольное. Надо найти максимальную сумму чисел из набора, которая не превышала бы контрольное число.
Задача почему-то запала мне в душу. Вернувшись домой, я быстро накатал решение: наивный перебор всех возможных сумм с выбором наилучшего. Сочетания я получал, перебирая все N-разрядные двоичные числа и беря суммы тех исходных чисел, которым соответствуют единицы. Но я с огорчением обнаружил, что при количестве элементов начиная где-то с 30, программа работает очень долго. Оно и не удивительно, ведь время работы такого алгоритма — n*2n (количество сочетаний, умноженное на длину суммы).
Почти во всех реализациях двоичного поиска и сортировки слиянием есть ошибка
3 min
Translation
Это перевод статьи Джошуа Блоха «Extra, Extra — Read All About It: Nearly All Binary Searches and Mergesorts are Broken» 2006 года.
Я живо помню первую лекцию Джона Бентли в университете Карнеги-Меллон, на которой он попросил нас, свежеиспечённых аспирантов, написать функцию двоичного поиска. Он взял одно из решений и разобрал его на доске, и, разумеется, в нём оказалась ошибка, как и во многих других наших попытках. Этот случай стал для меня наглядной демонстрацией к его книге «Жемчужины программирования». Мораль в том, чтобы внимательно расставлять инварианты в программе.
И вот, теперь 2006 год. Я был потрясён, узнав, что программа двоичного поиска, корректность которой Бентли доказывал формально и тестами, содержит ошибку. Не подумайте, что я придираюсь; по правде сказать, такая ошибка вполне может ускользать от тестеров десятилетиями. Более того, двоичный поиск, который я написал для JDK, тоже был багнутым лет девять. И только сейчас, когда она сломала кому-то программу, о ней сообщили в Sun.
Я живо помню первую лекцию Джона Бентли в университете Карнеги-Меллон, на которой он попросил нас, свежеиспечённых аспирантов, написать функцию двоичного поиска. Он взял одно из решений и разобрал его на доске, и, разумеется, в нём оказалась ошибка, как и во многих других наших попытках. Этот случай стал для меня наглядной демонстрацией к его книге «Жемчужины программирования». Мораль в том, чтобы внимательно расставлять инварианты в программе.
И вот, теперь 2006 год. Я был потрясён, узнав, что программа двоичного поиска, корректность которой Бентли доказывал формально и тестами, содержит ошибку. Не подумайте, что я придираюсь; по правде сказать, такая ошибка вполне может ускользать от тестеров десятилетиями. Более того, двоичный поиск, который я написал для JDK, тоже был багнутым лет девять. И только сейчас, когда она сломала кому-то программу, о ней сообщили в Sun.