
Этим постом мы хотели бы начать цикл статей, посвященных задаче изменения голоса. В зарубежной литературе данную задачу часто именуют термином voice morphing, в отечественной литературе данная задача ещё не получила достаточного освещения как в научных, так и в инженерных кругах. Тема является достаточно обширной и во многом творческой. В результате работы в данном направлении у нас накопился определенный опыт, который мы планируем систематизировать и изложить, а также передать основную суть некоторых алгоритмов.
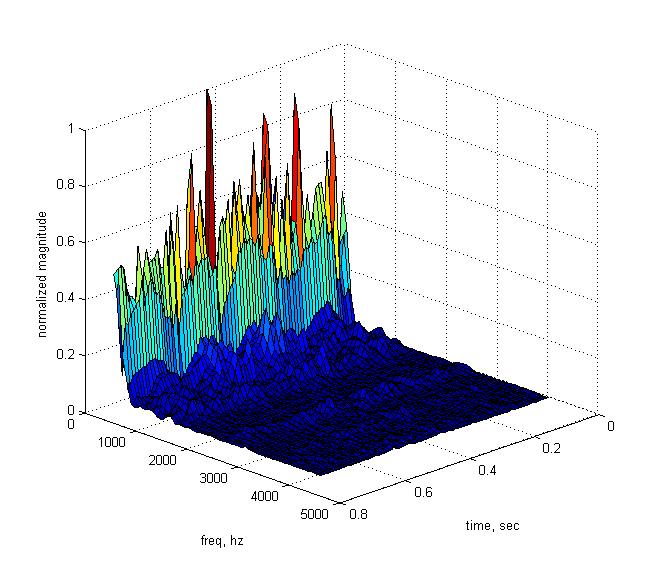
Изменение голоса может преследовать разную цель. Два основных направления, которые тут однозначно можно выделить – это получение реалистичного звучания измененного голоса и получение некоторого причудливо-фантастичного звучания. Неплохих результатов во втором случае вполне можно добиться, обрабатывая речевой сигнал как обычный звук, не заостряя внимание на его особенностях и делая многие допущения. Например, индустрия электронной музыки породила колоссальное количество разнообразных аудио-эффектов и результат их применения к речевому сигналу помогает создать самый невероятный образ говорящего.
В задаче реалистичного изменения голоса применение «музыкальных» (назовем их так) аудио-эффектов может привнести искажения, не характерные для натуралистичного звучания речи. В подобном случае необходимо более точно понимать, из каких звуков состоит речь, как они образуются и какие их свойства являются критическими для восприятия. Проще говоря — необходимо производить анализ сигнала перед его обработкой. При автоматизированной обработке речевого сигнала в реальном времени этот анализ усложняется многократно, т.к. умножается количество неопределенностей, которые надо как-то попытаться разрешить, и сокращается количество применимых алгоритмов.
В ближайших статьях мы рассмотрим варианты простейшей реализации таких эффектов, как изменение пола говорящего и изменение возраста говорящего. Чтобы читатель лучше понимал, какие параметры сигнала будут изменяться, в первых статьях будут затронуты основные вопросы образования звуков речи и способы формального описания речевого сигнала. После этого уже будут обсуждаться конкретные предлагаемые алгоритмы изменения голоса, их сильные и слабые стороны.
P.S.
Добавил дополнительные ссылки на первоисточники
Изменение голоса может преследовать разную цель. Два основных направления, которые тут однозначно можно выделить – это получение реалистичного звучания измененного голоса и получение некоторого причудливо-фантастичного звучания. Неплохих результатов во втором случае вполне можно добиться, обрабатывая речевой сигнал как обычный звук, не заостряя внимание на его особенностях и делая многие допущения. Например, индустрия электронной музыки породила колоссальное количество разнообразных аудио-эффектов и результат их применения к речевому сигналу помогает создать самый невероятный образ говорящего.
В задаче реалистичного изменения голоса применение «музыкальных» (назовем их так) аудио-эффектов может привнести искажения, не характерные для натуралистичного звучания речи. В подобном случае необходимо более точно понимать, из каких звуков состоит речь, как они образуются и какие их свойства являются критическими для восприятия. Проще говоря — необходимо производить анализ сигнала перед его обработкой. При автоматизированной обработке речевого сигнала в реальном времени этот анализ усложняется многократно, т.к. умножается количество неопределенностей, которые надо как-то попытаться разрешить, и сокращается количество применимых алгоритмов.
В ближайших статьях мы рассмотрим варианты простейшей реализации таких эффектов, как изменение пола говорящего и изменение возраста говорящего. Чтобы читатель лучше понимал, какие параметры сигнала будут изменяться, в первых статьях будут затронуты основные вопросы образования звуков речи и способы формального описания речевого сигнала. После этого уже будут обсуждаться конкретные предлагаемые алгоритмы изменения голоса, их сильные и слабые стороны.
P.S.
Добавил дополнительные ссылки на первоисточники






 Chrome 28.0.1500.72 m,
Chrome 28.0.1500.72 m,  Firebug 1.11.3,
Firebug 1.11.3,  Firefox 22.0,
Firefox 22.0,  Opera 12.15 (версия до ухода с presto)
Opera 12.15 (версия до ухода с presto)

