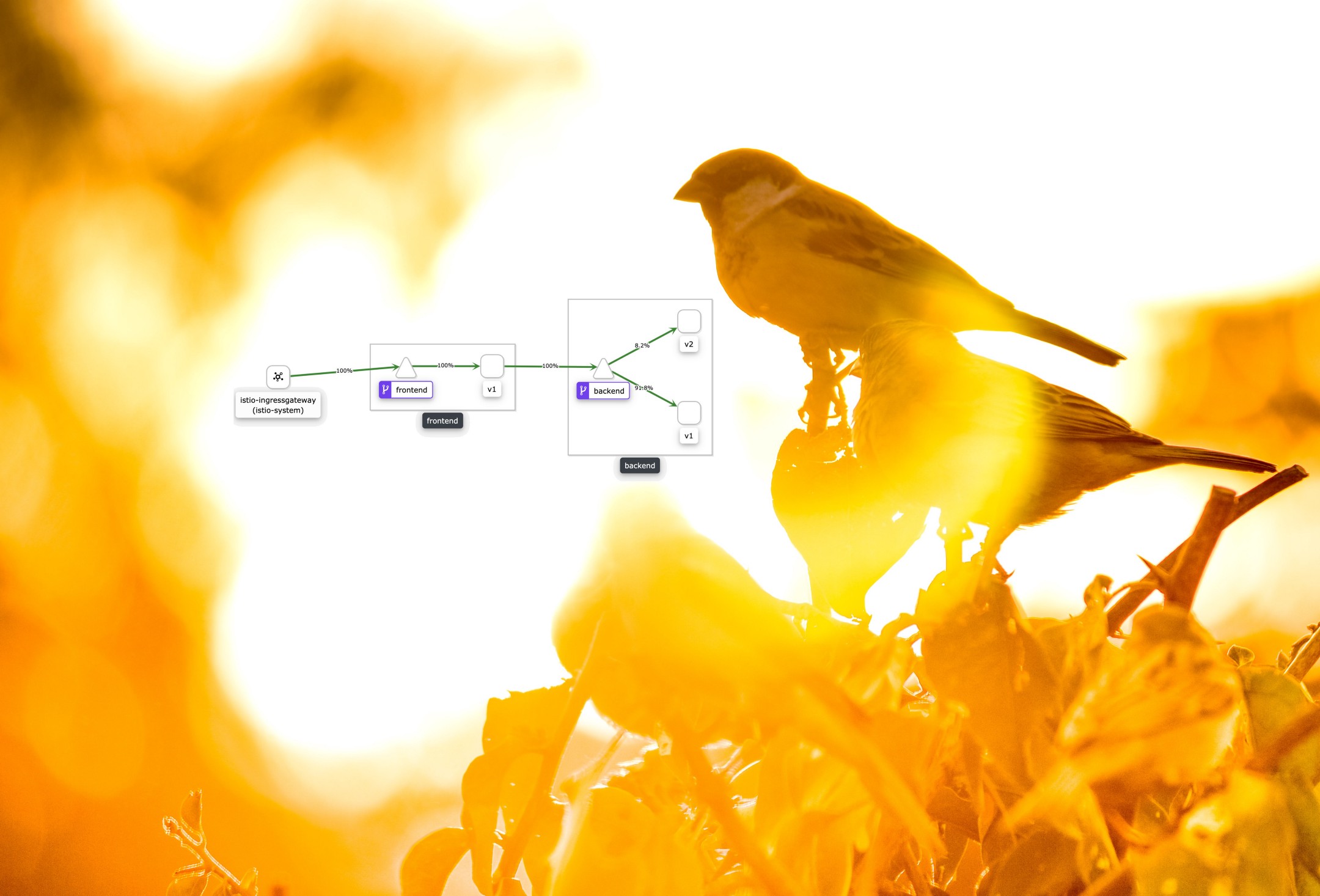
В настоящее время Kubernetes де-факто является стандартом для оркестрации контейнеров, и лично я использую Kubernetes в production уже более двух лет.
Будучи DevOps инженерами, мы тесно сотрудничаем с разработчиками и используем одни и те же инструменты такие, как: CI-CD, VCS, laC, мониторинг, логирование, оркестрацию контейнеров и т.д. Kubernetes также является одним из таких инструментов, который тоже используется во время разработки, развёртывания и отладки, устранения неполадок и мониторинга приложений. Как все знают, это требование DevOps культуры.