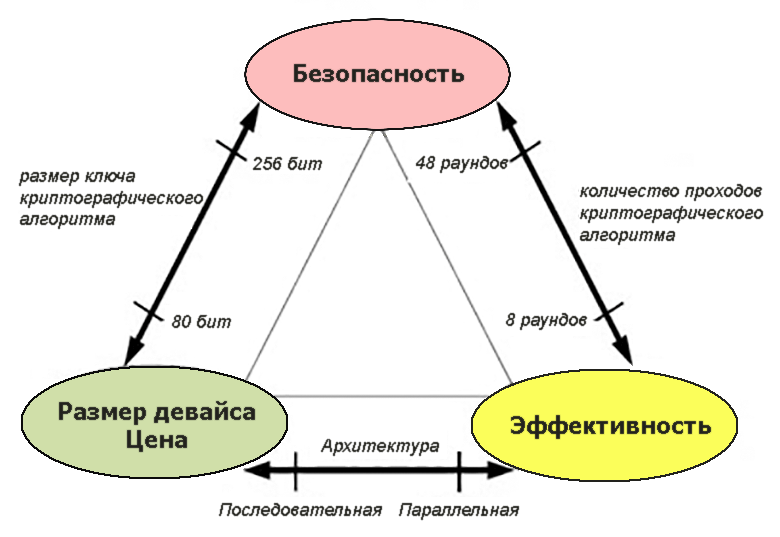
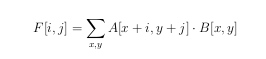Генерация текстуры с предписанными параметрами
Описание проблемы
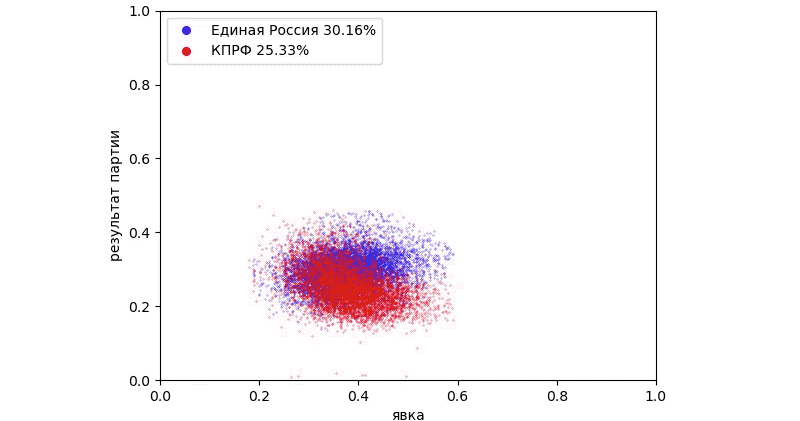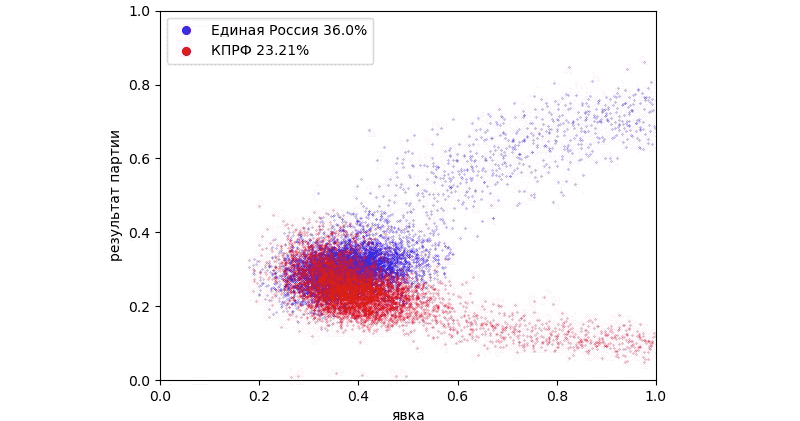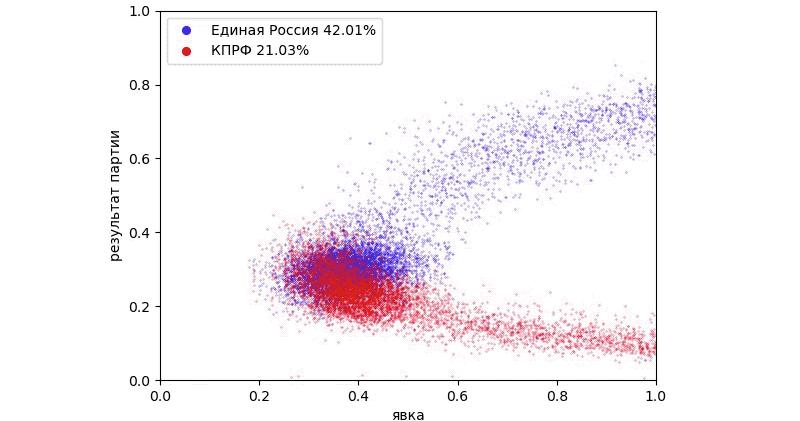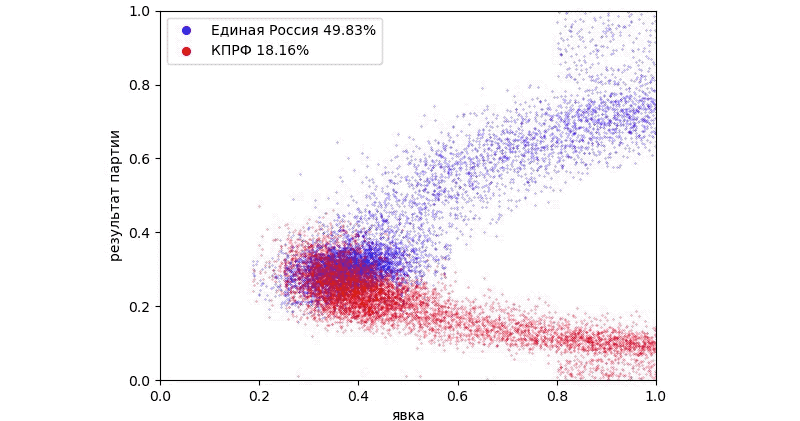
В компьютерной графике принято понимать под текстурой любое изображение, применяемое в реализации сцены. В теории цифровой обработки изображений текстуры это случайные поля. В данной статье рассматриваются случайные поля и способы из описания. Случайное поле есть функция F(x,y), значениями которой являются случайные величины. Если предполагается использовать значения этой функции в качестве генератора текстуры, то на значения поля накладываются дополнительные ограничения:
Все случайные величины z поля имеют одно и то же распределение.
Ковариация между F(x0,y0) и F(x1,y1) зависит только от вектора, соединяющего точки ( x0,y0) и (x1,y1) . (стационарность)
Важность выполнения указанного свойства случайного поля вытекает из следующей гипотезы.
Восприятие случайного поля человеком зависит только от значений ковариаций.
Не существует математического (статистического) доказательства справедливости данной гипотезы, но в практических исследованиях она считается выполненной.
Проблема состоит в разработке метода, с помощью которого можно получить текстуру с предписанной ковариационной функцией. Такая задача возникает, например, при отладке программ распознавания объектов, существенной характеристикой которых является случайная текстура (лес, поле, водная поверхность). Ограниченное применение эти текстуры имеют в компьютерной графике. Соответствующая ссылка приведена в конце статьи.