
Попытки открытия новой шашечной тактики или Что делать с несбыточной мечтой
13 мин
Введение
Спортивная игра «Шашки» является одной из игр человечества, которые компьютер ещё не просчитал полностью. Есть новости о том, что ученые нашли стратегию, при которой компьютер никогда не проиграет. За свои 9 лет, посвящённых этой игре, я встретил лишь одну программу, которую никак не мог победить. Пожалуй, мой спортивный опыт позволит сделать предположение, что это была программа реализующая стратегию описанную выше. К моему большому удивлению, она занимала лишь 60 Мбайт. А может быть, там была хорошо обученная нейронная сеть в основе? Но всё же мне не верится, что просчитать их невозможно. Там всего лишь 10^20 позиций, неужели мой компьютер не справится с такой задачей? А также, неужели нет тактики, в которой в начале партии соперник отдаёт шашку и оказываются в тактическом преимуществе?! Ни одного дебюта такого я не встречал. Пойду проверю…



 Lock-free list является основой многих интересных структур данных, — простейшего
Lock-free list является основой многих интересных структур данных, — простейшего 

 Приходит ветеринар к терапевту. Терапевт: — На что жалуетесь? Ветеринар: — Нет, ну так каждый может!
Приходит ветеринар к терапевту. Терапевт: — На что жалуетесь? Ветеринар: — Нет, ну так каждый может!


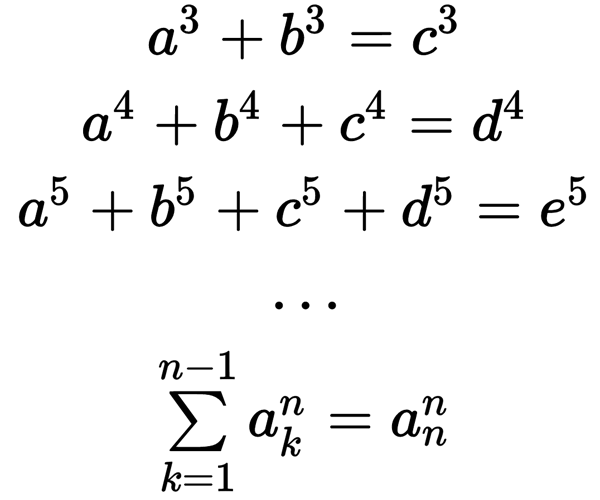

 В предыдущих частях опуса (
В предыдущих частях опуса (