Перевод поста Стивена Вольфрама (Stephen Wolfram) "Music, Mathematica, and the Computational Universe" о замечательном ресурсе WolframTones, работа которого была недавно возобновлена на новой площадке Wolfram Cloud (сайт, созданный в 2005 г., был недоступен пару лет, так как использовал не поддерживаемые современными браузерами решения).
Выражаю огромную благодарность Кириллу Гузенко за помощь в переводе.
Насколько сложно создать человеческую музыку? Такую, чтобы пройти музыкальный аналог
теста Тьюринга?
Хотя музыка обычно имеет определенную
формальную структуру, что отмечали пифагорейцы ещё 2500 лет назад, по своей сути она весьма
человечна: отражение чистого творчества, которое есть суть определяющая характеристика человеческих способностей.
Но что есть творчество? Это то, что было необходимо в течение всей биологической и культурной эволюции? И может ли оно также существовать в системах, которые не имеют ничего общего с людьми?
В своей работе над книгой
Новый вид науки (
A New Kind of Science) я исследовал вычислительную вселенную возможных программ и обнаружил, что даже очень простые программы могут показывать поразительно богатый и сложный характер, наравне, например, с тем, что можно встретить в природе. И, опираясь на разработанный
принцип вычислительной эквивалентности, я пришел к убеждению, что не может быть ничего, что принципиально отличает наши человеческие способности от любых процессов, которые происходят в природе, или даже в очень простых программах.
Но что можно сказать о музыке? Некоторые люди, выступая против принципа вычислительной эквивалентности, в качестве аргумента использовали свою веру в то, что "
не могут существовать простые программы, которые смогут произвести серьёзную музыку".
И мне стало любопытно:
действительно ли музыка есть что-то особенное и исключительно человеческое? Или всё таки её можно прекрасно создавать автоматически, с помощью вычислений?

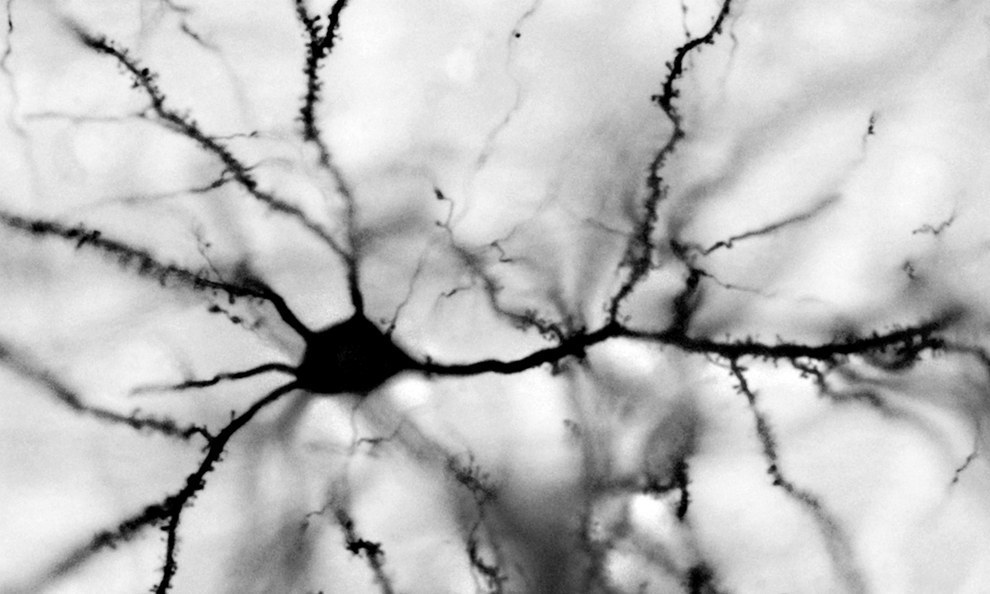 В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.
В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.



 Начнем разговор о мозге с несколько отвлеченной темы. Поговорим о клеточных автоматах. Клеточный автомат – это дискретная модель, которая описывает регулярную решетку ячеек, возможные состояния ячеек и правила изменений этих состояний. Каждая из ячеек может принимать конечное множество состояний, например, 0 и 1. Для каждой из ячеек определяется окрестность, задающая ее соседей. Состояние соседей и собственное состояние ячейки определяют ее следующее состояние.
Начнем разговор о мозге с несколько отвлеченной темы. Поговорим о клеточных автоматах. Клеточный автомат – это дискретная модель, которая описывает регулярную решетку ячеек, возможные состояния ячеек и правила изменений этих состояний. Каждая из ячеек может принимать конечное множество состояний, например, 0 и 1. Для каждой из ячеек определяется окрестность, задающая ее соседей. Состояние соседей и собственное состояние ячейки определяют ее следующее состояние. В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.
В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.