
Городская библиотека Стокгольма. Фото minotauria.
В этой статье я хочу рассказать о том, что оценивать время обращения к памяти как O(1) — это очень плохая идея, и вместо этого мы должны использовать O(√N). Вначале мы рассмотрим практическую сторону вопроса, потом математическую, на основе теоретической физики, а потом рассмотрим последствия и выводы.
Введение
Если вы изучали информатику и анализ алгоритмической сложности, то знаете, что проход по связному списку это O(N), двоичный поиск это O(log(N)), а поиск элемента в хеш-таблице это O(1). Что, если я скажу вам, что все это неправда? Что, если проход по связному списку на самом деле O(N√N), а поиск в хеш-таблице это O(√N)?
Не верите? Я вас сейчас буду убеждать. Я покажу, что доступ к памяти это не O(1), а O(√N). Этот результат справедлив и в теории, и на практике. Давайте начнем с практики.
Измеряем
Давайте сначала определимся с определениями. Нотация “О” большое применима ко многим вещам, от использования памяти до запущенных инструкций. В рамках этой статьи мы O(f(N)) будет означать, что f(N) — это верхняя граница (худший случай) по времени, которое необходимо для получения доступа к N байтов памяти (или, соответственно, N одинаковых по размеру элементов). Я использую Big O для анализа времени, но не операций, и это важно. Мы увидим, что центральный процессор подолгу ждет медленную память. Лично меня не волнует, что делает процессор пока ждет. Меня волнует лишь время, как долго выполняется та или иная задача, поэтому я ограничиваюсь определением выше.




 Что такое информация, как найти скрытый в ней смысл, что вообще есть смысл? В большинстве толкований
Что такое информация, как найти скрытый в ней смысл, что вообще есть смысл? В большинстве толкований 





 Привет, Хабражитель!
Привет, Хабражитель!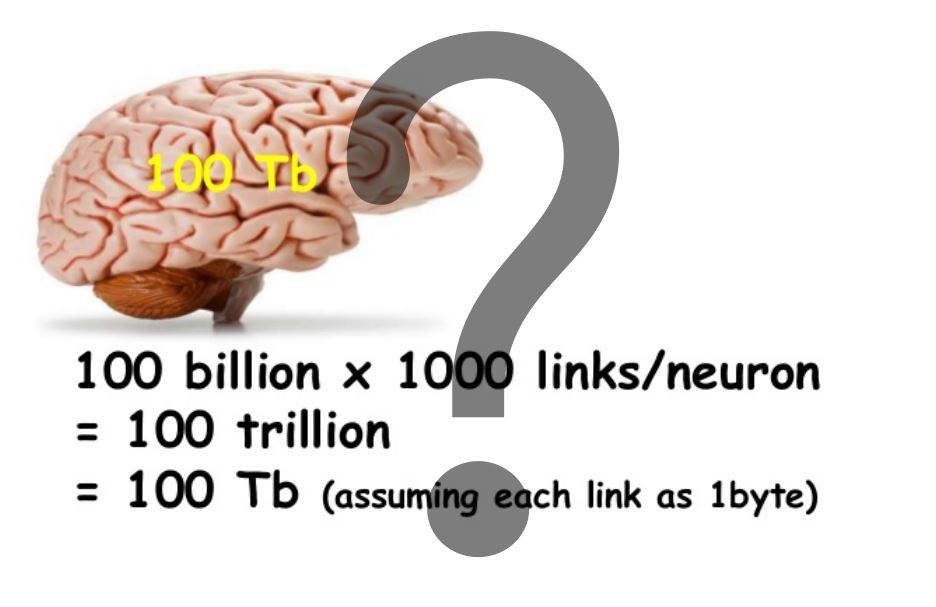 Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.
Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.
") ,
, )") — пересечение полуплоскостей,
— пересечение полуплоскостей, )") — алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
— алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).