YT: зачем Яндексу своя MapReduce-система и как она устроена
14 мин
В течение последних шести лет в Яндексе идет работа над системой под кодовым называнием YT (по-русски мы называем её «Ыть»). Это основная платформа для хранения и обработки больших объемов данных — мы уже о ней рассказывали на YaC 2013. С тех пор она продолжала развиваться. Сегодня я расскажу о том, с чего началась разработка YT, что нового в ней появилось и что ещё мы планируем сделать в ближайшее время.

Кстати, 15 октября в офисе Яндекса мы расскажем не только о YT, но и о других наших инфраструктурных технологиях: Media Storage, Yandex Query Language и ClickHouse. На встрече мы раскроем тайну — расскажем, сколько же в Яндексе MapReduce-систем.
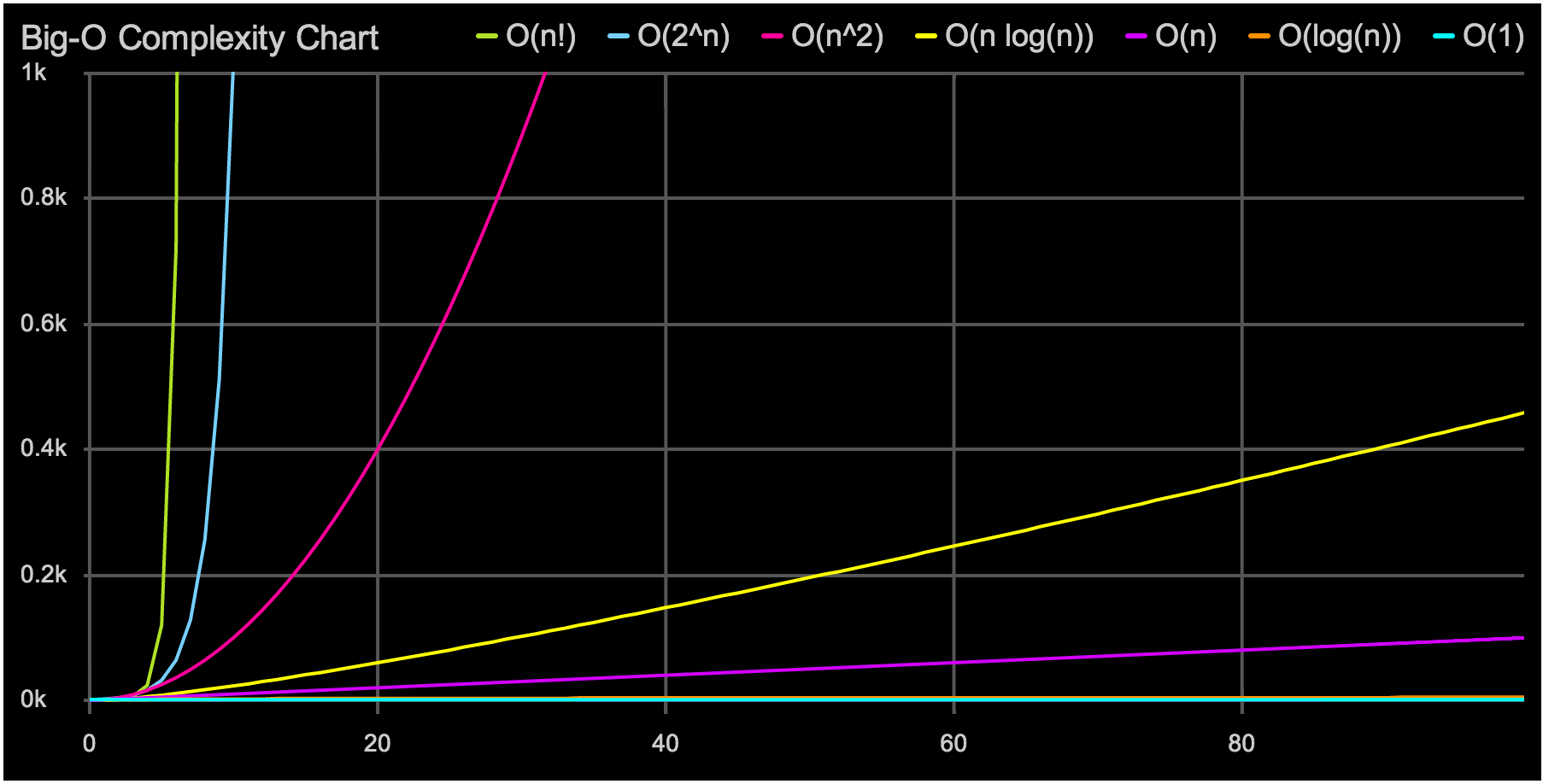
По роду своей деятельности Яндекс постоянно сталкивается с необходимостью хранить и обрабатывать данные таких объемов, с которыми обычному пользователю никогда не приходится иметь дело. Поисковые логи и индексы, пользовательские данные, картографическая информация, промежуточные данные и результаты алгоритмов машинного обучения — все это может занимать сотни петабайт дискового пространства. Для эффективной обработки подобных объемов традиционно используется парадигма MapReduce, позволяющая достичь хорошего баланса между эффективностью вычислений и простотой пользовательского кода.
Кстати, 15 октября в офисе Яндекса мы расскажем не только о YT, но и о других наших инфраструктурных технологиях: Media Storage, Yandex Query Language и ClickHouse. На встрече мы раскроем тайну — расскажем, сколько же в Яндексе MapReduce-систем.
Какую задачу мы решаем?
По роду своей деятельности Яндекс постоянно сталкивается с необходимостью хранить и обрабатывать данные таких объемов, с которыми обычному пользователю никогда не приходится иметь дело. Поисковые логи и индексы, пользовательские данные, картографическая информация, промежуточные данные и результаты алгоритмов машинного обучения — все это может занимать сотни петабайт дискового пространства. Для эффективной обработки подобных объемов традиционно используется парадигма MapReduce, позволяющая достичь хорошего баланса между эффективностью вычислений и простотой пользовательского кода.



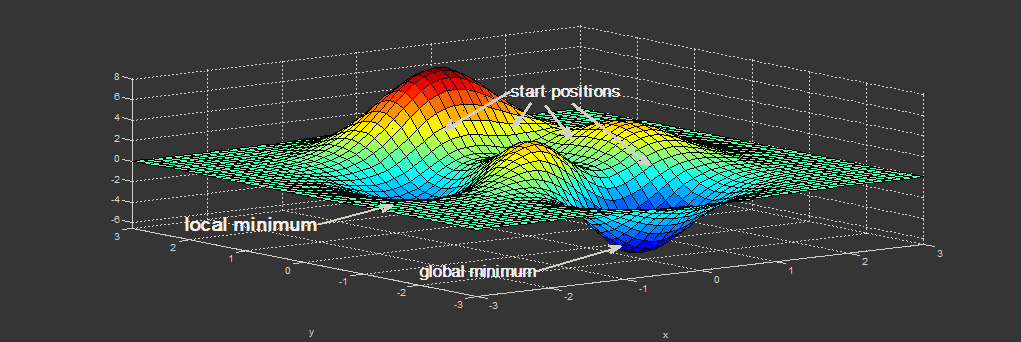
") ,
, )") — пересечение полуплоскостей,
— пересечение полуплоскостей, )") — алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
— алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).