Найти объект или распознать понятие в тексте — с этого начинается решение большинства NLP задач. Если вы проектируете поисковую систему, создаете голосового помощника или классифицируете пользовательские запросы, прежде всего вы должны разобрать входной текст и попытаться найти в нем
именованные сущности, которые могут быть универсальными, такими как даты, страны и города, или специфичными для конкретной модели. Обратите внимание, мы сейчас говорим лишь о тех видах задач, для которых заранее известно, что именно вы ищете или что может встретиться в тексте.
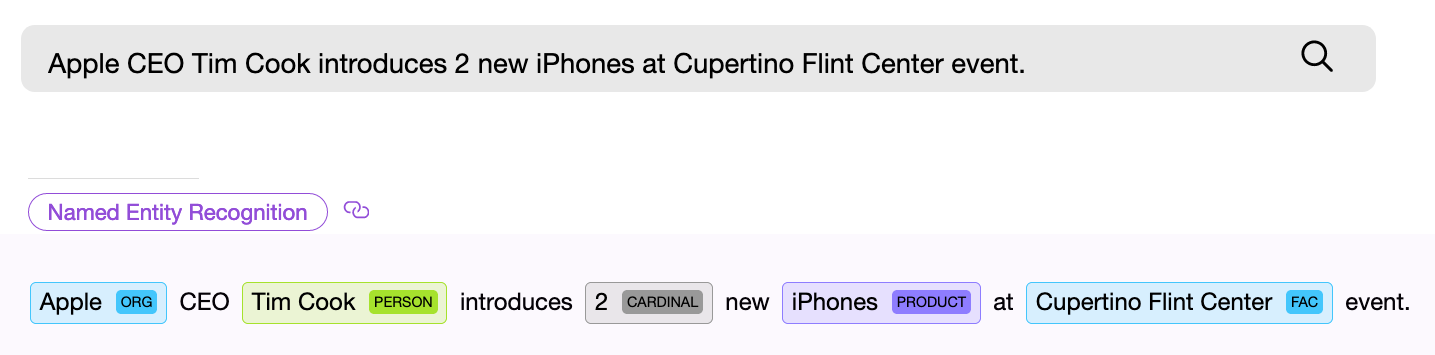
NER (named entity recognition) компонент, то есть программный компонент для поиска именованных сущностей, должен найти в тексте объект и по возможности получить из него какую-то информацию. Пример — “Дайте мне
двадцать две маски”. Числовой NER компонент находит в приведенном тексте словосочетание “двадцать две” и извлекает из этих слов числовое нормализованное значение — “
22”, теперь это значение можно использовать.
NER компоненты могут базироваться на нейронных сетях или работать на основе правил и каких-либо внутренних моделях. Универсальные NER компоненты часто используют второй способ.
Рассмотрим несколько готовых решений по поиску стандартных сущностей в тексте. В данной заметке мы остановимся на бесплатных или бесплатных с ограничениями библиотеках, а также расскажем о том, что сделано в проекте
Apache NlpCraft в рамках данной проблематики. Представленный ниже список не является подробным и обстоятельным обзором, которых и так достаточное количество в сети, а скорее кратким описанием основных особенностей, плюсов и минусов использования этих библиотек.