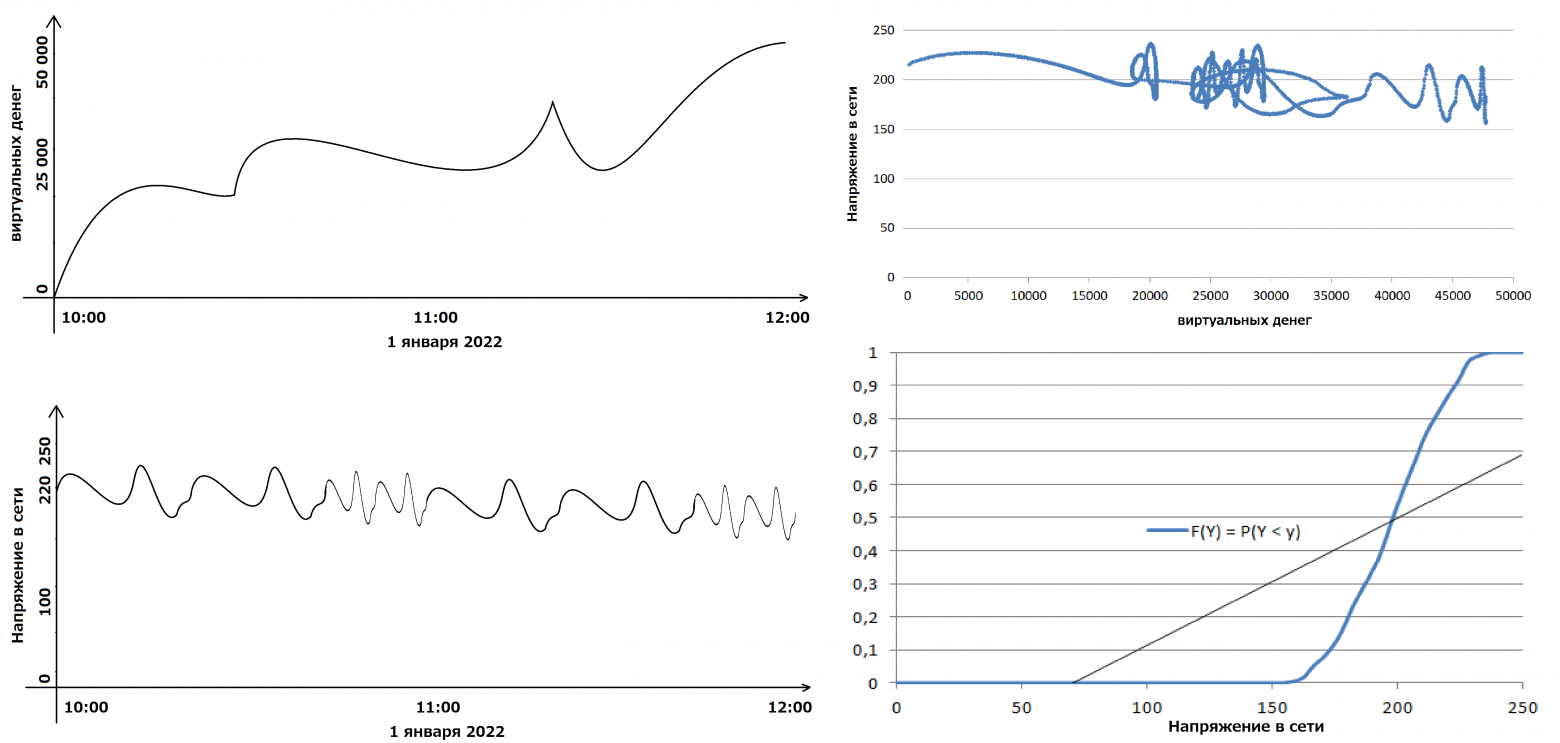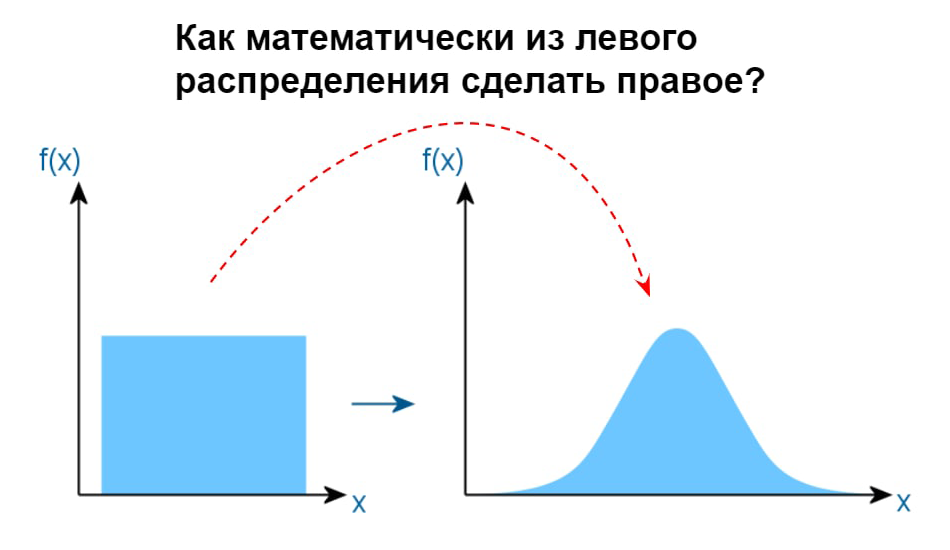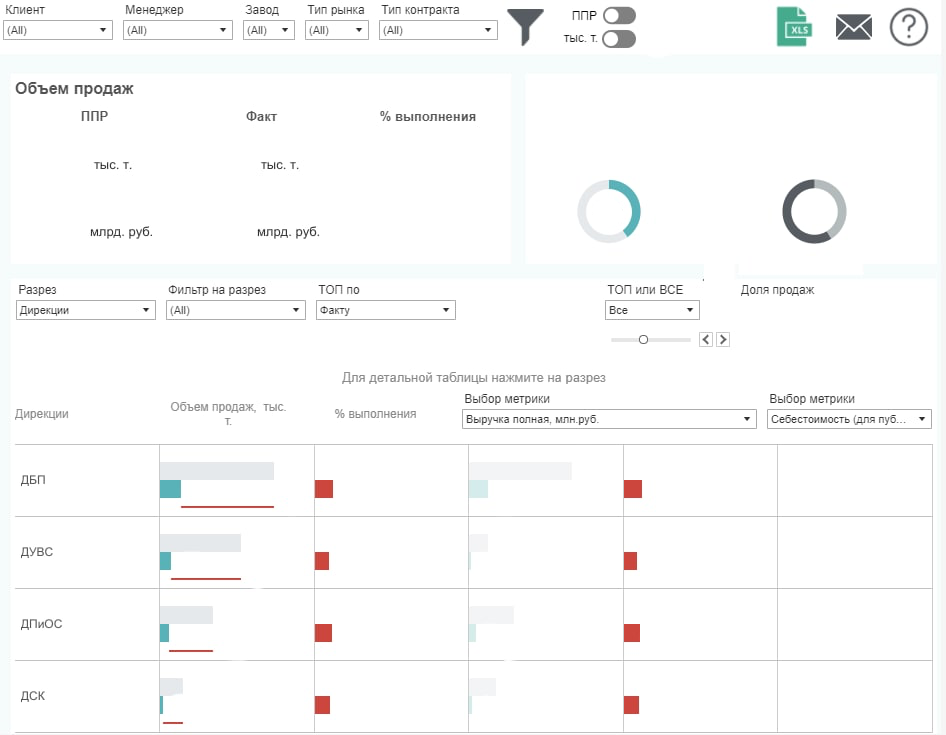
Привет! Как мы уже не раз рассказывали, СИБУР поделен на несколько сквозных процессов. Сквозные процессы – это бизнес-домены, которые объединяют в себе бизнес-команды одной сферы. У нас таких много, но конкретно этот пост будет посвящён дашбордам для O2C.
В случае O2C – это также сквозной процесс, который расшифровывается как Order to cash. Он отвечает за привлечение новых клиентов и получение прибыли. Кроме того, такой подход помогает перестраивать бизнес-процессы на предприятии и способствует активной цифровизации производственных процессов.
Сегодня использование O2C напрямую связано с промышленной цифровизацией. Постепенно все, начиная от поиска лидов и сопровождения сделок, заканчивая непосредственно продажами, передачей права собственности, когда бухгалтерия контрагента расписалась в акте, перестраивается на автоматический режим.
O2C как бизнес состоит из нескольких больших подразделений, эти же подразделения являются как потребителями данных, так и основными генераторами идей, все-таки стараемся работать в продуктовом подходе и учитывать хотелки всех и вся, как минимум внутри O2C.