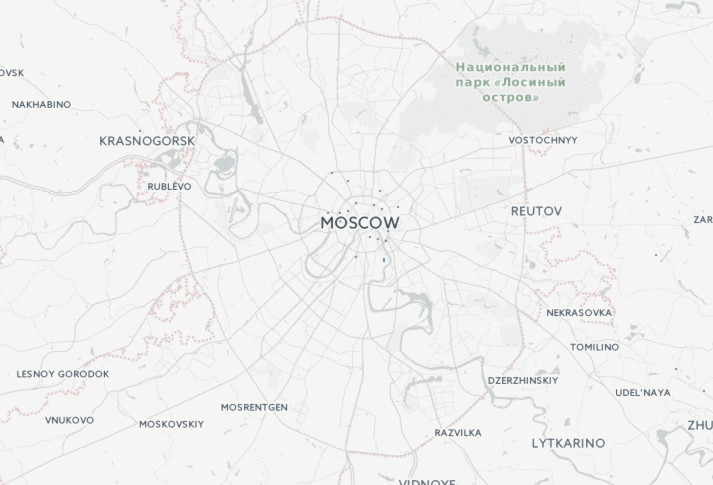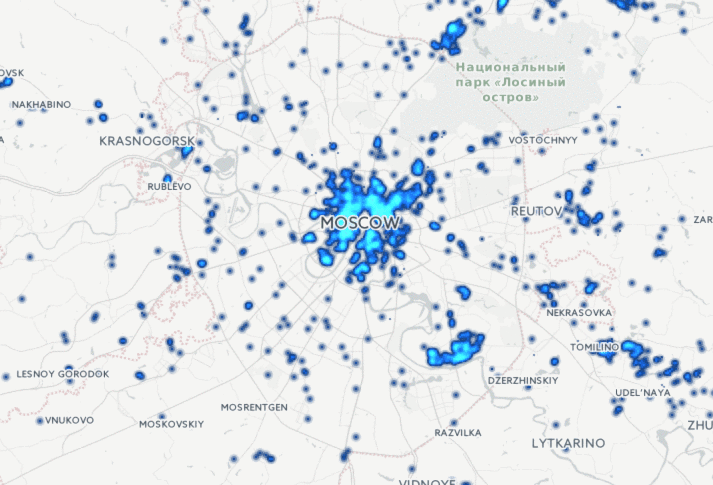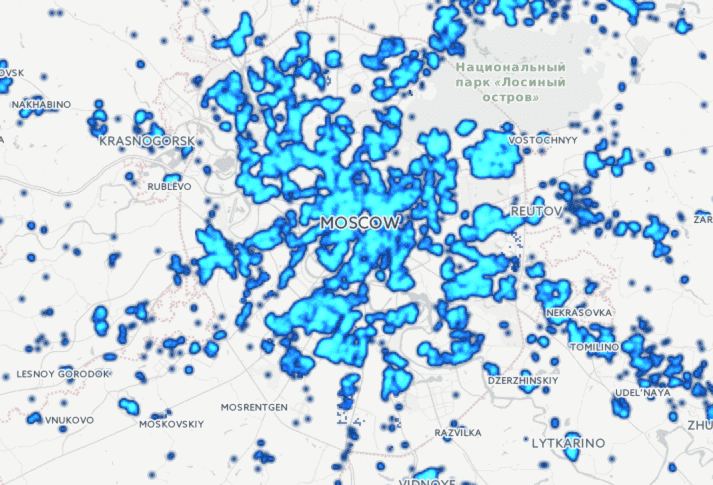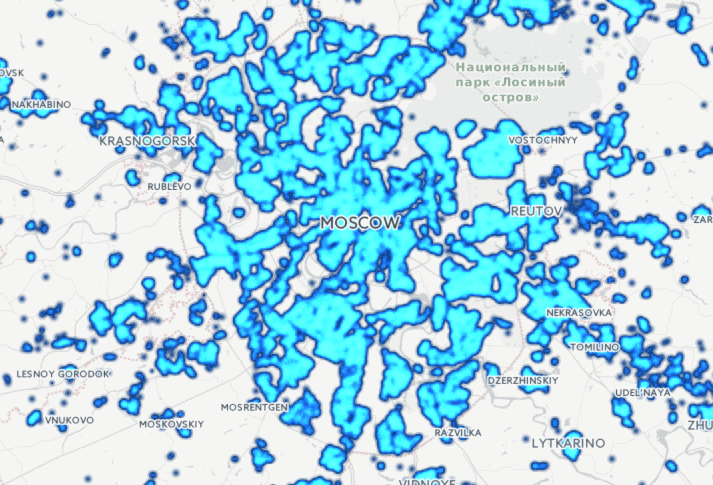
Как данные в руках разведчиков аналитиков Palantir превращаются из неструктурированных в структурированные.
Palantir — частная американская компания, четвертый по капитализации (после Uber, Xiaomi и Airbnb) стартап в мире (данные на начало 2016 года). Основные заказчики — ЦРУ, военные, ЦКЗ и крупные финансовые организации.
По-моему, как-то так видели пользу информационных технологий «отцы-основатели» Вэнивар Буш («As We May Think»), Дуглас Энгельбарт («The Mother of All Demos») и Джозеф Ликлайдер («Интергалактическая компьютерная сеть» и «Симбиоз человека и компьютера»), о которых я писал немного ранее.
Под катом — два кейса (2010 года).
(За помощь с переводом спасибо Ворсину Алексею)
Palantir — частная американская компания, четвертый по капитализации (после Uber, Xiaomi и Airbnb) стартап в мире (данные на начало 2016 года). Основные заказчики — ЦРУ, военные, ЦКЗ и крупные финансовые организации.
По-моему, как-то так видели пользу информационных технологий «отцы-основатели» Вэнивар Буш («As We May Think»), Дуглас Энгельбарт («The Mother of All Demos») и Джозеф Ликлайдер («Интергалактическая компьютерная сеть» и «Симбиоз человека и компьютера»), о которых я писал немного ранее.
Под катом — два кейса (2010 года).
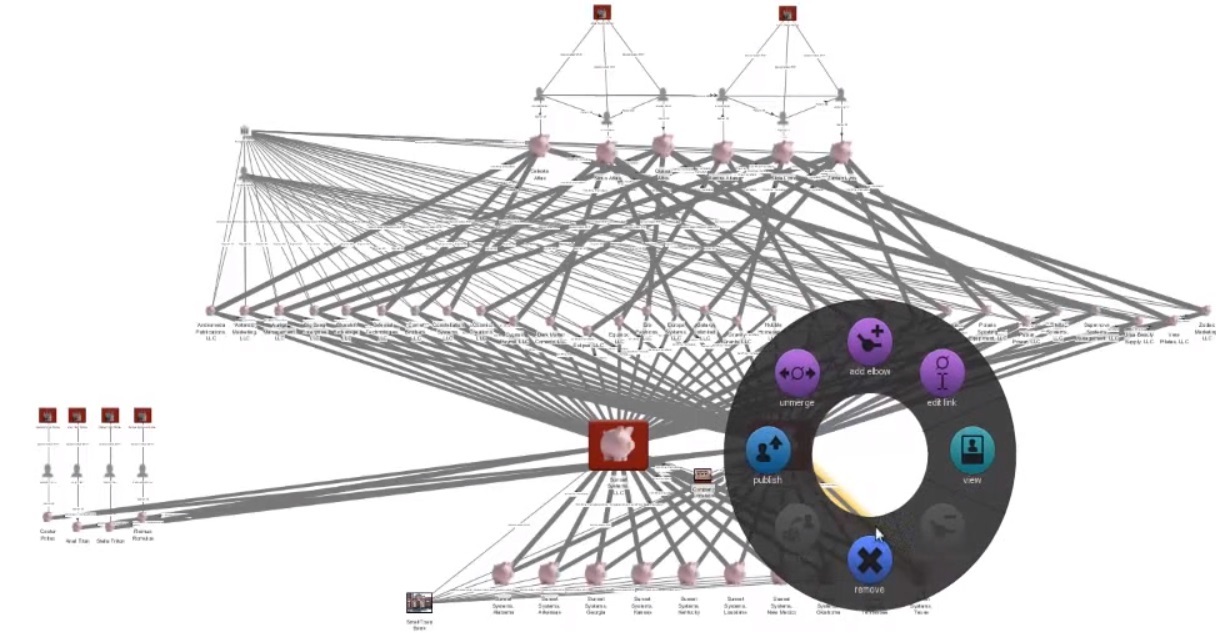
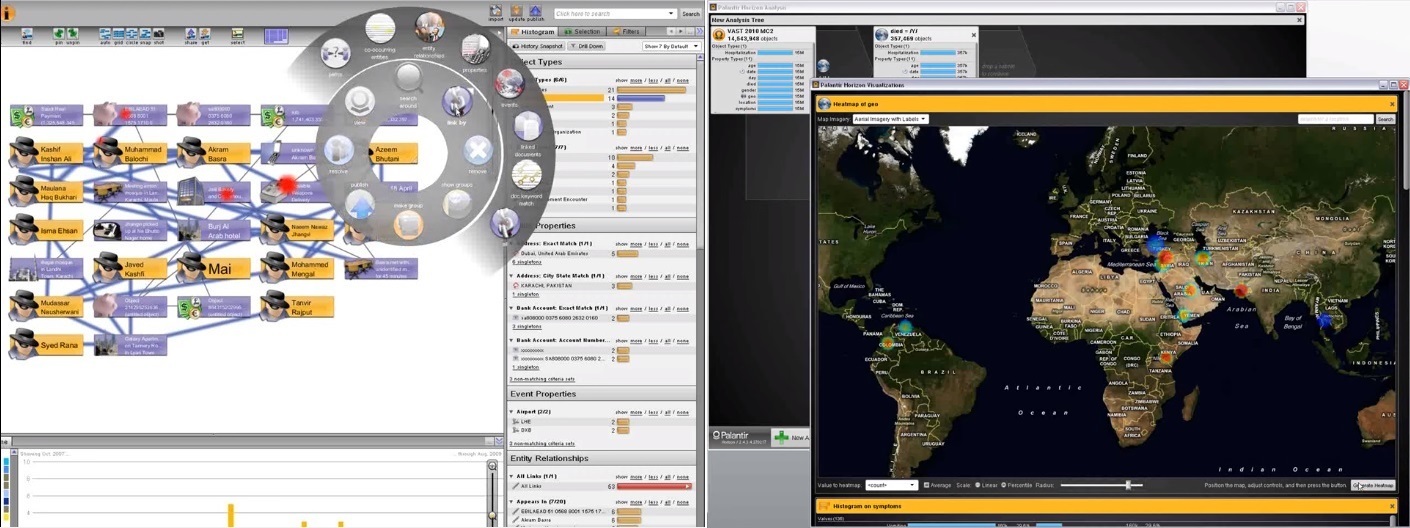
- Первый — анализ распространения вируса во время национальной пандемии на основе пятнадцати миллионов записей обращений в больницу и трехсот пятидесяти семи тысячах записей о смерти.
- Второй — анализ сотни отчетов из расследования по глобальной сети торговцев оружием.
(За помощь с переводом спасибо Ворсину Алексею)