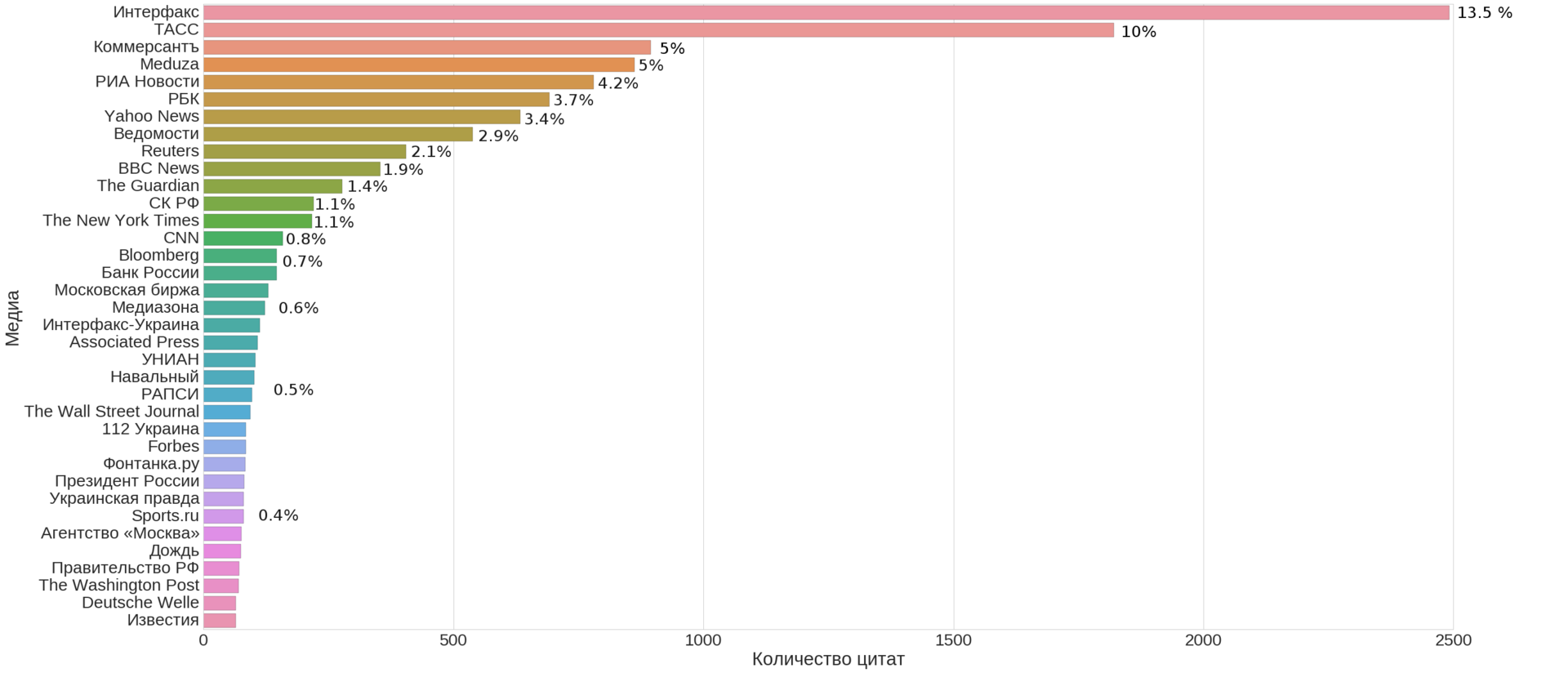
В первой части этой серии статей вы узнали о данных и о том, как можно использовать компьютеры чтобы добывать смысловое значение из крупных блоков таких данных. Вы даже видели что-то похожее на большие данные у Amazon.com середины девяностых, когда компания запустила технологию для наблюдения и записи в реальном времени всего, что многотысячная аудитория клиентов одновременно делала на их сайте. Довольно впечатляюще, но назвать это большими данными можно с натяжкой, пухлые данные — больше подойдёт. Организации вроде Агентства национальной безопасности США (NSA) и Центра правительственной связи Великобритании (GCHQ) уже собирали большие данные в то время в рамках шпионских операций, записывая цифровые сообщения, хотя у них и не было простого способа расшифровать их и найти в них смысл. Библиотеки правительственных записей были переполнены наборами бессвязных данных.
То, что сделал Amazon.com, было проще. Уровень удовлетворённости их клиентов мог быть легко определен, даже если он охватывал все десятки тысяч продуктов и миллионы потребителей. Действий, которые клиент может совершить в магазине, реальный он или виртуальный, не так уж много. Клиент может посмотреть что в доступе, запросить дополнительную информацию, сравнить продукты, положить что-то в корзину, купить или уйти. Всё это было в пределах возможностей реляционных баз данных, где отношения между всеми видами действий возможно задать заранее. И они должны быть заданы заранее, с чем у реляционных баз данных проблема — они не так легко расширяемы.
Заранее знать структуру такой базы данных — как составить список всех потенциальных друзей вашего неродившегося ребенка… на всю жизнь. В нём должны быть перечислены все неродившиеся друзья, потому что как только список будет составлен, любое добавление новой позиции потребует серьезного хирургического вмешательства.

 Хабр, привет! Приглашаем вас на форум Data Science Week, который проходит при поддержке DCA.
Хабр, привет! Приглашаем вас на форум Data Science Week, который проходит при поддержке DCA. 


 Spark – проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight.
Spark – проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight.