Компания Palantir является четвертой по крутости частной компанией Кремниевой долины (после Uber, Xiaomi и Airbnb). Пока Palantir собирает информацию про все на свете, мы собираем информацию про него.

ИТишники додумались как эффективно «монетизировать математику и алгоритмы» (Сегалович, Бакунов), PayPal Mafia додумалась как монетизировать
гаджеты Феанора философию (капитализация Palantir — 20 миллиардов долларов).
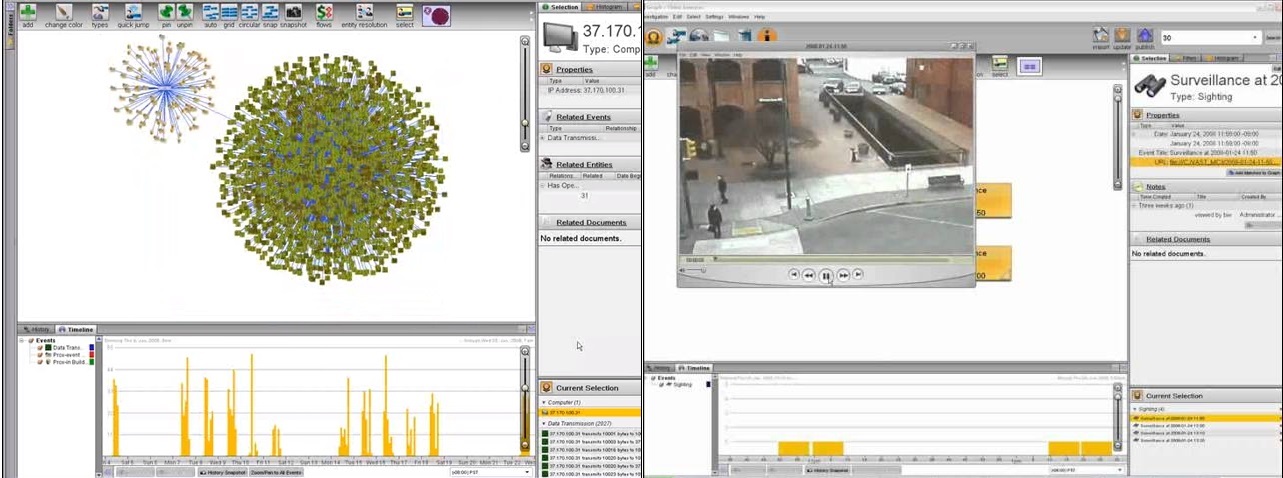
В десятиминутной лекции сотрудник компании Palantir расскажет про центральную концепцию их системы — динамическую онтологию.

0:00 Привет, я Ашер Синенски, инженер по развертыванию технологий Palantir. Я поговорю о динамической онтологии.
0:08 Очевидно, сейчас, эти два слова выглядят для вас довольно туманно, надеюсь, что к концу разговора вы поймете, какой смысл мы в них вкладываем.
0:17 Перед тем как переходить к делу, поясню: у многих людей проблемы со словом онтология. Что мы подразумеваем под этим словом?
0:24 Если вы посмотрите на корни этого слова, то оно образовано от греческих «онтос» (бытие) и «логия» (изучение чего-либо). По сути, онтология – это категоризация мира.
0:34 Есть много терминов, которые люди используют для описания этого: таксономия, схематизатор модели данных. Но мы используем это, в более широком смысле, как идею, что мы действительно категоризируем мир каким-то образом.
0:43 Идея о построении онтологии для изучения мира не нова. Первым, кто утвердил эту идею, был мужик по имени Платон. Идея Платоновского реализма, в основном, о том, что есть реальные вещи, а есть наше представление о вещах.