Как знания нейропсихологии могут помочь программисту в стилизации кода? До того, как заняться программированием, я очень долго и глубоко изучал нейропсихологию. Впоследствии эти знания помогли мне добиться высоких результатов в разработке за короткий промежуток времени.
В этой статье я хочу поделиться своим опытом и подходом к стилизации кода. Мы рассмотрим стилизацию со стороны программирования, а затем немного коснемся нейропсихологии для более глубокого понимания самого процесса и степени его важности для разработчика. Последний год я работаю в компании Secreate, где занимаюсь разработкой мобильных приложений на фреймворке React Native, поэтому примеры кода, приведенные в этой статье, будут на языке Javascript. Знания, полученные из этой статьи, можно будет легко применить к любому языку программирования. В конце статьи вас ждут полезные примеры стилизации кода. Приятного чтения!
Что такое стилизация
Каждый программист имеет свое представление о code style. Для меня стилизация — это набор правил для оформления, таких как: отступы, пробелы, переносы, последовательность и так далее. Тем не менее, каждый программист оформляет свой код по-своему. Давайте рассмотрим несколько примеров такого оформления.
Импорты
Некоторые программисты пишут их так:
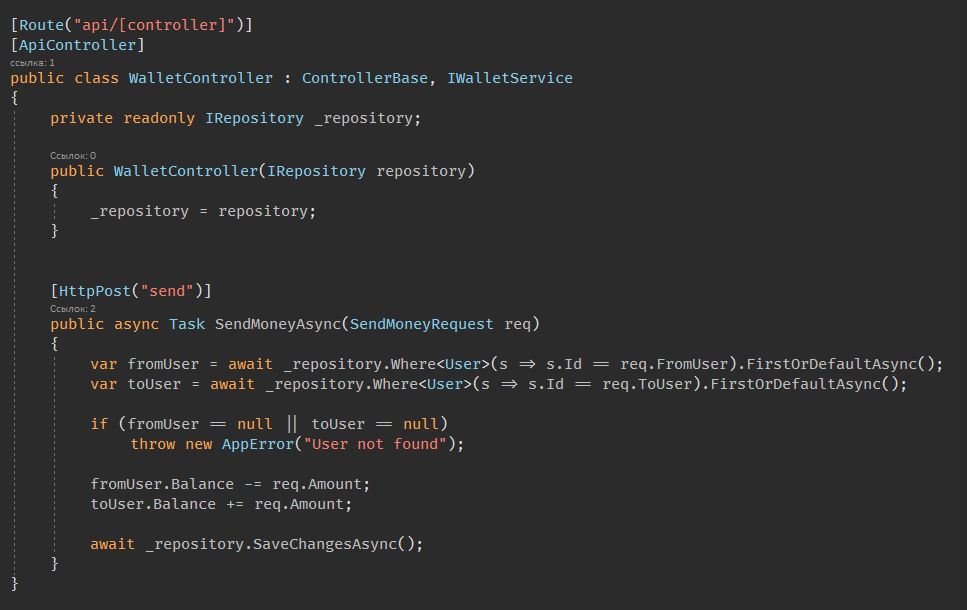
import {SomeClass} from ‘some/file’
Некоторые так:
import { SomeClass } from ‘some/file’
Еще можно встретить такое:
import {SomeClass, someFunction, someConst, AnotherClass и еще много чего в длинную строку} from ‘some/file’
Или такое:
import {
SomeClass,
somefunction,
someConst,
AnotherClass,
и еще много чего в столбик
} from ‘some/file’
Объявление функций