
Progrobot: бот справки по языкам программирования
5 мин
Когда пишешь код, регулярно бывает нужно посмотреть справку по конкретной функции, модулю и т.д. Обычно я для этого захожу на cppreference.com или на docs.python.org, но это обычно не мгновенно — требует перехода по нескольким страницам минимум, а в питоновской документации еще и зачастую просто сложно найти нужную информацию на странице, не говоря уж о том, что гугл часто направляет на документацию по второй версии, а не по третьей, и приходится вручную переключать.
Поэтому я подумал, что может быть полезен телеграм-бот, который будет всю эту информацию знать и выдавать по запросу справку по конкретной функции, классу, модулю и т.п.
Так получился бот @Progrobot. Ему можно отправить название функции и получить ее краткое описание, можно послать название модуля (в питоне) или заголовочного файла (в c++) и получить список всех функций в этом модуле, и т.д. Пока есть справка по c++ (с cppreference) и python3 (с docs.python.org). Еще планировал сделать поиск по stackoverflow, но оказалось, что API-шный поиск работает плохо, да еще и есть жесткое ограничение на количество запросов — короче, пока отключил, потом, может быть, выкачаю offline-базу и допилю.
Поэтому я подумал, что может быть полезен телеграм-бот, который будет всю эту информацию знать и выдавать по запросу справку по конкретной функции, классу, модулю и т.п.
Так получился бот @Progrobot. Ему можно отправить название функции и получить ее краткое описание, можно послать название модуля (в питоне) или заголовочного файла (в c++) и получить список всех функций в этом модуле, и т.д. Пока есть справка по c++ (с cppreference) и python3 (с docs.python.org). Еще планировал сделать поиск по stackoverflow, но оказалось, что API-шный поиск работает плохо, да еще и есть жесткое ограничение на количество запросов — короче, пока отключил, потом, может быть, выкачаю offline-базу и допилю.

") ,
, )") — пересечение полуплоскостей,
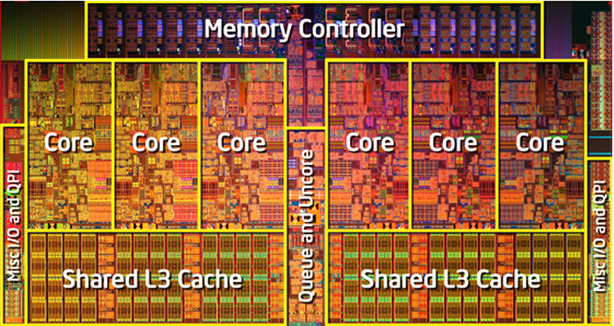
— пересечение полуплоскостей, )") — алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
— алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
 Я регулярно проверяю различные открытые проекты, чтобы продемонстрировать возможности статического анализатора кода PVS-Studio (C, C++, C#). Настало время компилятора GCC. Бесспорно, GCC — это очень качественный и оттестированный проект, поэтому найти в нём хотя бы несколько ошибок уже большое достижение для любого инструмента. К моей радости, PVS-Studio справился с этой задачей. Никто не застрахован от опечаток и невнимательности. Именно поэтому PVS-Studio может стать вашей дополнительной линией обороны на фронте бесконечной войны с багами.
Я регулярно проверяю различные открытые проекты, чтобы продемонстрировать возможности статического анализатора кода PVS-Studio (C, C++, C#). Настало время компилятора GCC. Бесспорно, GCC — это очень качественный и оттестированный проект, поэтому найти в нём хотя бы несколько ошибок уже большое достижение для любого инструмента. К моей радости, PVS-Studio справился с этой задачей. Никто не застрахован от опечаток и невнимательности. Именно поэтому PVS-Studio может стать вашей дополнительной линией обороны на фронте бесконечной войны с багами.



