
Сжимаем изображения без потерь: какой формат выбрать?
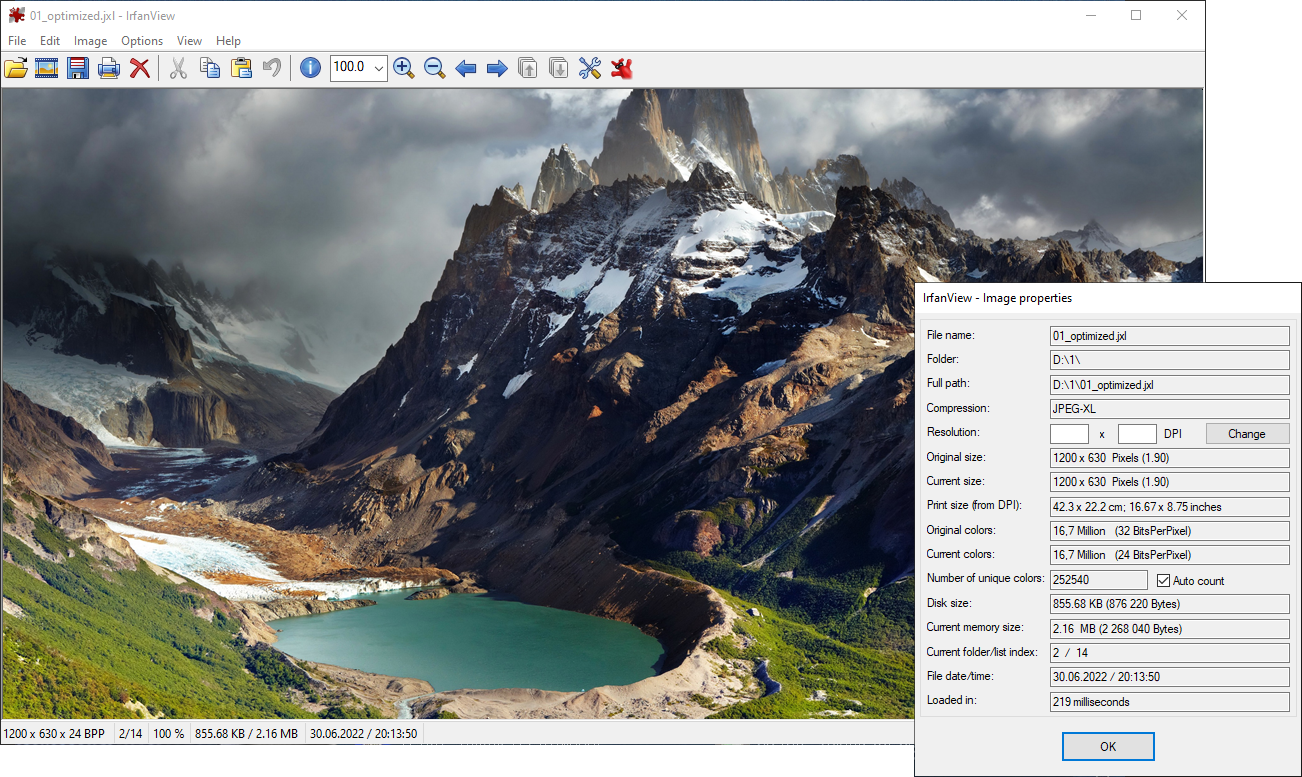
Одна из тестовых фотографий, сжатие без потерь на 41%
Для сжатия изображений без потерь принято использовать PNG. Его обычно применяют для логотипов, скриншотов, диаграмм, где есть сплошные области с одинаковым цветом. Такие области сжимаются лучше всего: все lossless-кодеки используют классический RLE, то есть кодирование повторов. В некоторых случаях это обеспечивает даже лучший коэффициент сжатия, чем JPEG. И никаких искажений.
Но PNG не используют для фотографий — файлы слишком большие. Однако сейчас, с появлением кодеков нового поколения, ситуация должна измениться. Фотографии будут кодировать без потерь в файлы меньшего размера, а PNG наконец-то уйдёт на покой (см. результаты тестирования в конце статьи).
Кто круче rsync? Интересные алгоритмы для синхронизации данных

Тридж, автор rsync
Что может быть приятнее, чем минимизировать объём бэкапа или апдейта? Это не просто экономия ресурсов, а чистая победа интеллекта над энтропией Вселенной. Исключительно силой разума мы уменьшаем размер файла, сохраняя прежний объём информации в нём, тем самым уменьшая поток фотонов в оптоволокне и снижая температуру CPU. Реальное изменение физического мира силой мысли.
Если без шуток, то все знают rsync — инструмент для быстрой синхронизации файлов и каталогов с минимальным трафиком, который пришёл на замену
rcp и scp. В нём используется алгоритм со скользящим хешем, разработанный австралийским учёным, программистом и хакером Эндрю Триджеллом по кличке Тридж (на фото).Алгоритм эффективный, но не оптимальный.
Нейронная (де)компрессия материала — нелинейное уменьшение размерности основанное на данных
В этом посте я возвращаюсь к том, к чему не собирался возвращаться — уменьшению размерности и сжатию полного набора текстур материала (в отличие от единичных текстур) — крайне неисследованной области.
В одном из моих предыдущих постов я описал как простейшая линейная корреляция может быть использована для значительного уменьшения размерности набора текстур материала, а в другом посте рискнул пойти дальше в увлекательную область словарей и разреженного сжатия.
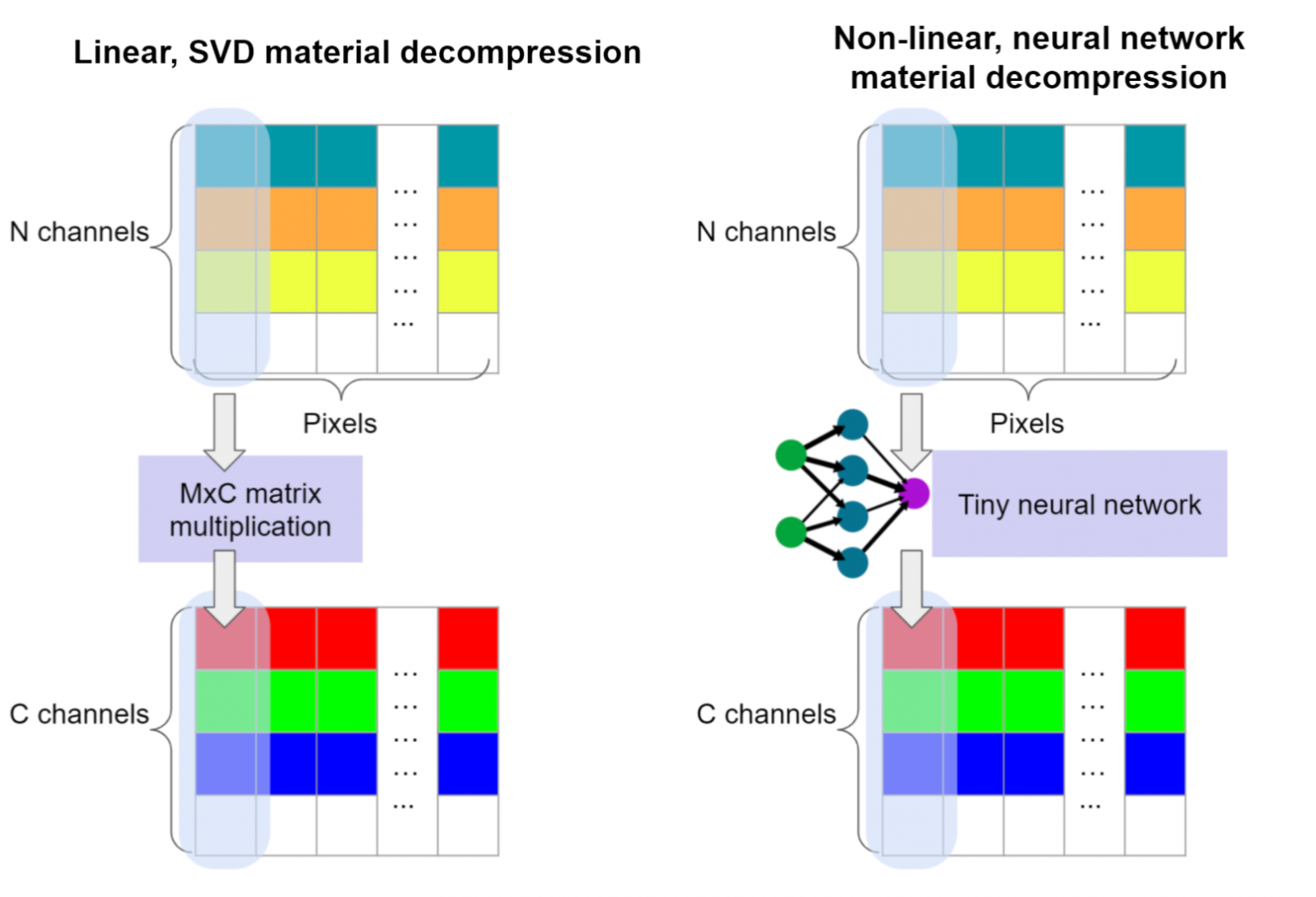
В этот раз я опишу как мы можем оставить мир простых линейных корреляций (который мы исследовали, используя SVD) и использовать техники основанные на данных (машинное обучение!) для изучения нелинейных функций, используя дифференцируемое программирование / нейронные сети.
Первый митап фронтенд-гильдии Росбанка: шакализация, GraphQL и микроархитектура

Привет! Недавно мы провели небольшой митап для фронтендеров, куда пригласили троих интересных спикеров. Наш коллега Игорь Борзунов рассказал о том, как решать проблемы с плохим качеством изображений. Даниил Водолазкин из X5Tech поведал о неочевидных сложностях работы с GraphQL. И завершил программу Георгий Конюшков из «Леруа Мерлен» с темой «Time to market: микрофронтенды». В этом посте мы свели основные тезисы всех трех докладов.
Как Windows 11 уменьшила размер кумулятивных обновлений на 40%
Раз в месяц Microsoft выпускает кумулятивное обновление Windows, которое включают в себя все предыдущие. То есть для приведения системы в актуальное состояние требуется установка единственного апдейта.
Учитывая огромное количество исправлений в Windows, кумулятивное обновление без оптимизации может сильно вырасти в размере, что неприемлемо. Например, его не смогут скачать пользователи с медленным подключением к интернету, а только в США таких 20%. Поэтому уменьшение размера обновлений — приоритетная задача. Теперь для неё нашлось решение.
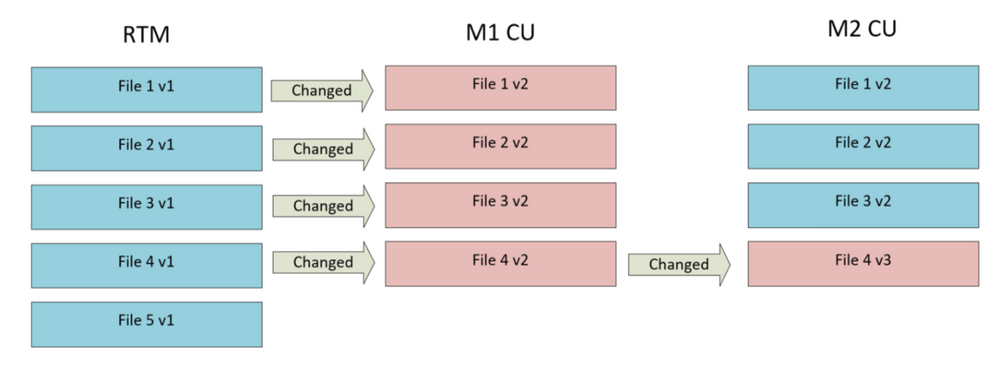
Если вкратце, то раньше каждое обновление включало в себя прямую дельту изменений системы, а также обратную дельту для приведения системы к базовой RTM, чтобы установить новую прямую дельту через месяц. Однако выяснилось, что обратную дельту можно вычислить в процессе установки обновления. Теперь Microsoft намерена запатентовать этот алгоритм.
Архитектурные паттерны в распределенных высоконагруженных системах

Всякая сложная инфраструктура, поступательно развивавшаяся на протяжении длительного времени, содержит в себе набор разных архитектурных неоптимальностей, а то и откровенных недостатков. Порой эти недостатки становятся неожиданным препятствием для внедрения новых сервисов. Инфраструктура М.Видео-Эльдорадо в этом отношении не является исключением, в чем мы признаемся без излишней рефлексии. Но что с этим делать? Как сделать систему надежной и пригодной для дальнейшего развития? За ответами мы пришли к Александру Алехину, директору по развитию ИТ архитектуры.
Как развитие алгоритмов сжатия остановилось 20 лет назад, или о новом конкурсе на 200 тысяч евро

В октябре прошлого года я опубликовал статью «О талантах, деньгах и алгоритмах сжатия данных», где с юмором описал, как «изобретают» новые алгоритмы сжатия люди, не имеющие достаточно навыков для реализации своих идей. А заодно рассказал про существующие конкурсы по новым алгоритмам, в том числе двигавшийся тогда к завершению конкурс алгоритмов сжатия с призовым фондом 50 тысяч евро.
Пост набрал 206 «плюсов», вышел на 2 место топа недели и вызвал оживленную дискуссию, в которой мне больше всего понравился комментарий: «Коммерческого интереса эффективность по сжатию алгоритмов сжатия без потерь сегодня не представляет, в силу отсутствия принципиально более эффективных алгоритмов. Деньги сегодня — в сжатии аудио-видео. И там и алгоритмы другие. Тема сжатия без потерь удобна именно лёгкостью верификации алгоритма, и не слегка устарела. Лет на 20.»
Поскольку я сам уже 20 лет в области сжатия видео, с ее бурным развитием мне спорить сложно. А вот что сжатие без потерь развиваться перестало… Хотя логика тут понятна каждому. Я до сих пор пользуюсь ZIP, все мои друзья пользуются ZIP с 1989 года — значит, ничего нового не появляется. Так ведь? Похоже рассуждают сторонники плоской земли. ))) Я не видел, знакомые не видели, и даже некоторые авторитеты утверждают, значит, это так!
О том, как Intel просили меня не прекращать читать курс по сжатию, ибо людей нет новые алгоритмы делать, я в прошлый раз писал. Но тут и Huawei в ту же дуду дует! Вместо того, чтобы раздать призы
Развивались ли алгоритмы сжатия без потерь в последние 20 лет? Чем закончился прошлый конкурс и на сколько опередили baseline? Сколько денег получили русские таланты, а сколько зарубежные? И есть ли вообще жизнь
Кому интересно — добро пожаловать под кат!
Защищает ли Netflix свой контент?

Наверное всё, что нужно знать про DRM, защиту контента и продвинутые водяные знаки.
Часть I, про DRM
Главная проблема для Netflix'а и других стримингов — слив контента на торренты, в общий доступ. Ну и последующее снижение количества подписчиков сервиса.
Чтобы избежать плачевной ситуации онлайн-кинотеатры защищают контент всеми силами, используя DRM и водяные знаки по указке правообладателей. Сначала расскажу про DRM.
Расширенные возможности MessagePack

MessagePack — бинарный формат сериализации данных, позиционируемый авторами как более эффективная альтернатива JSON. Благодаря своей компактности и скорости, его часто выбирают в качестве формата обмена данными в системах, где важна производительность. Простота реализации также способствует его широкому распространению — ваш любимый язык программирования, скорее всего, уже имеет несколько библиотек для работы с этим форматом.
В этой статье я не буду рассказывать, как устроен MessagePack или сравнивать его с аналогами: материалов на эту тему в Интернете предостаточно. Чего действительно не хватает, так это информации о расширенной системе типов MessagePack. Я постараюсь объяснить и показать на примерах, что это такое и как с помощью дополнительных типов сделать сериализацию еще более эффективной.
Профессор Яаков Зив: автор метода сжатия данных без потерь

Яаков Зив разработал то, что мы привыкли называть термином lossless data compression — сжатие данных без потерь. Его работы стали основой для технологий, которыми мы пользуемся и по сей день, от GIF и PDF до ZIP и MP3.
Должно быть, Зив сказочно богат? Увы, нет.
Почему tar.xz-файлы, созданные с Python tar, оказались в 15 раз меньше, чем у macOS tar

Прим. перев.: это не совсем обычный перевод, потому что в его основе не отдельно взятая статья, а недавний случай со Stack Exchange, ставший главным хитом ресурса в этом месяце. Его автор задает вопрос, ответ на который можно отнести к базовым знаниям в области ИТ, но в то же время оказавшийся откровением для некоторых посетителей сайта.
Сжимая каталоги по ~1,3 ГБ, в каждом из которых по 1440 файлов JSON, я обнаружил 15-кратную разницу между размером архивов, сжатых с помощью tar на macOS или Raspbian 10 (Buster), и архивов, полученных при использовании библиотеки tarfile, встроенной в Python.
Что такое HDR10+? Разбор
Давайте взглянем на картинку. Вроде ничего необычного. Но что если я вам скажу, что ячейки A и B — совершенного одного цвета.


На самом деле мы не всегда можем отличить светлое от темного. Далеко за примерами ходить не надо: помните сине-черное / бело-золотое платье или появившиеся чуть позже кроссовки?


И все современные экраны пользуются этой особенностью человеческого зрения. Вместо настоящего света и тени нам показывают их имитацию. Мы настолько к этому привыкли, что даже не представляем что может быть как-то иначе. Но на самом деле может. Благодаря технологии HDR, которая намного сложнее и интереснее, чем вы думаете. Поэтому сегодня мы поговорим, что такое настоящее HDR-видео, поговорим про стандарты и сравним HDR10 и HDR10+ на самом продвинутом QLED телевизоре!
На самом деле первое, что надо знать про HDR: это не просто штука, которая правильно хранит видео. Чтобы увидеть HDR-контент нам нужно две составляющие: сам контент, и правильный экран, который его поддерживает. Поэтому смотреть мы сегодня будем на QLED-телевизоре Samsung.
Ближайшие события
Как Apple H.265 втихую продвигает

Всем привет! Я являюсь пользователем техники всем известной Купертиновской компании Apple, думаю как и многие из читателей Хабра. Я не ярый фанат яблока, просто меня устраивают устройства которые выпускает Apple. У меня в распоряжении несколько Iphone и планшет Ipad pro, так же не брезгую и устройствами на Android. Осенью 2020-го года у меня выдалось две недели отпуска. Чтобы не поддаваться осенней хандре (а она у меня бывает каждую осень), я решил махнуть в Питер и устроить себе мини путешествие дней на 5-7. Думаю погуляю, поснимаю видео и может сделаю мини ролик о путешествии.
Кодирование для чайников, ч.1

Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
Внизу читаем апдейт.
Как мы создаём почтовую систему нового поколения Mailion. Эффективное объектное хранилище для электронной почты

Недавно на Хабре вышли две статьи про новую корпоративную почтовую систему Mailion от МойОфис (1, 2) — уникальную российскую разработку, которая отличается беспрецедентными возможностями масштабирования и способна работать в системах с более чем 1 миллионом пользователей.
Несложно подсчитать, что для обслуживания такого числа пользователей потребуется колоссальный объем дискового пространства вплоть до десятков петабайт. При этом почтовая система должна уметь быстро обрабатывать эту информацию и надежно хранить её. Сегодня мы объясним общие принципы организации хранения данных внутри почтовой системы Mailion и расскажем, к каким оптимизациям мы прибегли, чтобы значительно снизить количество операций ввода/вывода и сократить требования к инфраструктуре.
Windows 95 на двух флоппиках

Общий подход я уже описывал в комментариях: создаётся RAMDRIVE, и на него разворачивается двухтомный SFX-архив. Но есть много тонкостей:
- Как видно на видео выше, распакованная папка Windows у меня занимает 6.2 МБ. Я взял за основу список файлов Micro95, и дополнительно удалил файлы, оказавшиеся необязательными — например, шрифты и драйвер
dosnet.vxd. Кроме того,vmm32.vxdя распаковал, и удалил бывшие внутри него необязательные драйвера.
Использование ИИ для сверхсжатия изображений
Управляемые данными алгоритмы, такие как нейронные сети, взяли мир штурмом. Их развитие вызвано несколькими причинами, в том числе дешевым и мощным оборудованием и огромным объемом данных. Нейронные сети в настоящее время находятся в авангарде во всем, что касается «когнитивных» задач, таких как распознавание изображений, понимание естественного языка и т.д. Но они не должны ограничиваться такими задачами. В этом материале рассказывается о способе сжатия изображений с помощью нейронных сетей, при помощи остаточного обучения. Представленный в статье подход работает быстрее и лучше стандартных кодеков. Схемы, уравнения и, конечно, таблица с тестами под катом.
Ещё один велосипед: храним юникодные строки на 30-60% компактнее, чем UTF-8
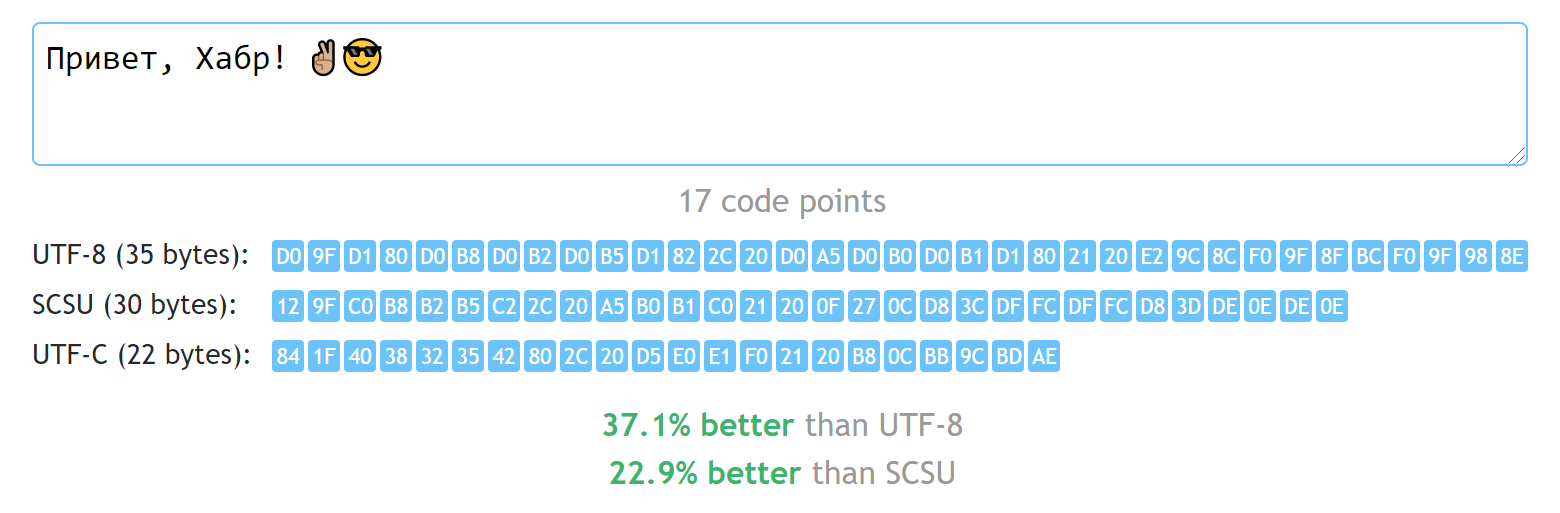
Если вы разработчик и перед вами стоит задача выбора кодировки, то почти всегда правильным решением будет Юникод. Конкретный способ представления зависит от контекста, но чаще всего тут тоже есть универсальный ответ — UTF-8. Он хорош тем, что позволяет использовать все символы Юникода, не тратя слишком много байт в большинстве случаев. Правда, для языков, использующих не только латиницу, «не слишком много» — это как минимум два байта на символ. Можно ли лучше, не возвращаясь к доисторическим кодировкам, ограничивающим нас всего 256 доступными символами?
Ниже предлагаю ознакомиться с моей попыткой дать ответ на этот вопрос и реализацию относительно простого алгоритма, позволяющего хранить строчки на большинстве языков мира, не добавляя той избыточности, которая есть в UTF-8.
Сжатие видео на пальцах: как работают современные кодеки?

Затраты на хранение данных зачастую становятся основным пунктом расходов при создании системы видеонаблюдения. Впрочем, они были бы несравнимо больше, если бы в мире не существовало алгоритмов, способных сжимать видеосигнал. О том, насколько эффективны современные кодеки, и какие принципы лежат в основе их работы, мы и поговорим в сегодняшнем материале.