Фильтруйте больше — тратьте меньше с последней версией Cloudera Data Warehouse Runtime
5 мин
Перевод

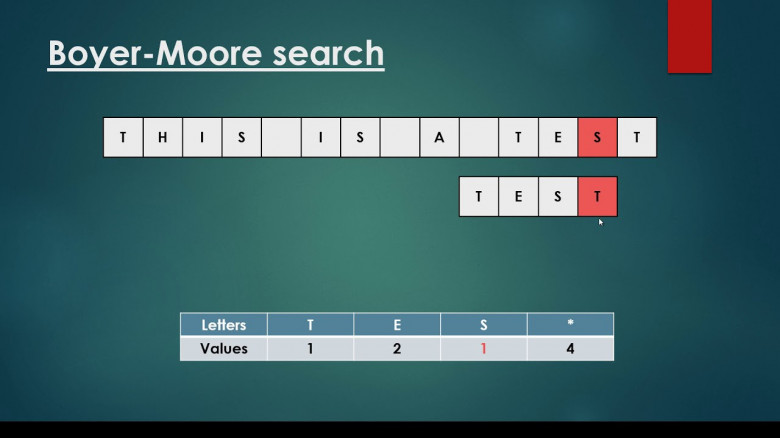
Сегодня одним из наиболее эффективных способов повышения производительности и минимизации затрат в системах баз данных является отказ от излишних операций, таких как чтение данных с уровня хранения (например, с дисков или из удаленного хранилища), их передача по сети или даже материализация данных при выполнении запроса. Apache Hive изначально улучшает выполнение распределенных запросов, передавая предикаты фильтров столбцов обработчикам подсистемы хранения, таким как HBase, или «читателям» данных в колоночном формате, например Apache ORC. Оценка этих предикатов вне механизма выполнения дает меньше данных для оценки запроса (сокращение данных) и приводит к уменьшению времени выполнения запроса и количества операций ввода-вывода.