Модели глубокого обучения обладают потрясающим свойством — они
становятся лучше с увеличением объёма данных, и кажется, что этот процесс практически неограничен. Чтобы получить качественно работающую модель, недостаточно больших объёмов данных, нужны ещё и точные аннотации. Хотя большие объёмы данных помогают модели решать проблему несогласованности данных в разных аннотациях, люди всё равно могут совершать повторные ошибки, укореняющиеся в модели.
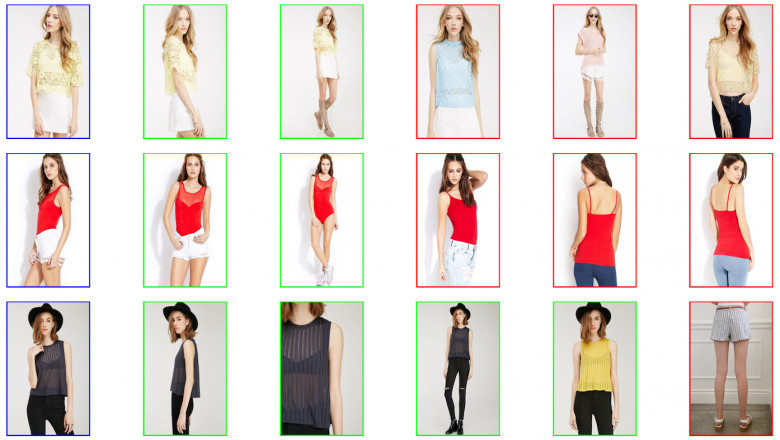
Например, когда человеку нужно нарисовать вокруг объекта прямоугольник, он обычно стремится, чтобы объект точно попал в этот прямоугольник, то есть склонен ошибаться в сторону увеличения прямоугольника. Использование такой модели для избегания столкновений приведёт к ложноположительным результатам, из-за чего беспилотный транспорт будет останавливаться без причины.
Превышение размера ограничивающих прямоугольников — пример систематической ошибки, а бывают ещё и случайные. Случайные и систематические ошибки влияют на обученную модель по-разному.