Машинное обучение может помочь в достаточно большом количестве задач логистической сфере. Это не только задачи для компаний, которые работают в этой сфере, но и для бизнеса, который пользуется услугами логистических компаний: дистрибьюторы, компании FMCG, ретейлеры и т.д. Я говорю о задачах, начиная с базовых (проверка автомобилей перед выездом на безопасность) и заканчивая оптимизацией работы склада за счет машинного обучения.
В городской логистике есть два направления, где можно использовать машинное обучение. Первое – автоматизация доставки. Например, у «Яндекса» есть роботы-курьеры, которые сейчас ездят по Москве (от места отправки заказа до адреса получателя) и обучаются, автоматические дроны Amazon успешно развозят заказы клиентам в пилотном режиме.
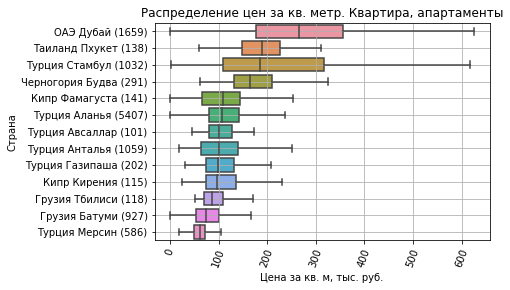
Второе направление - построение маршрутов для доставки покупок, более проработанная область, поскольку машинное обучение помогает не столько построить маршрут, сколько скорректировать его. У того же «Яндекса» есть большая проблема – он плохо предсказывает пробки и влияние погодных условий на дорожный трафик. Даже если вы просто ездите на такси, можно заметите, что цена 300 рублей, ехать 10 минут. Но это в 17.55 вечера, когда все едут с работы домой и, хотя цена небольшая, на одного клиента водитель потратит минут 40. Вот это никак не учитывается.
Однако, есть менее изученное направление в логистике с точки зрения пользы для него машинного обучения - это полное планирование маршрутов для доставки на день, неделю, месяц по нескольким точкам для энного количества автомобилей. Речь идет как о всем известной задаче коммивояжера, так и более частном - так называемые задачи VRP, которые сейчас решаются по большей части эврестическими алгоритмами. И у этих решений есть определенные проблемы.