Исторически, модель работы сервера PostgreSQL выглядит как множество независимых процессов с частично разделяемой памятью. Каждый из них обслуживает только
одно клиентское подключение и один запрос в любой момент времени — и никакой многопоточности.
Поэтому внутри каждого отдельного процесса нет никаких традиционных «странных» проблем с параллельным выполнением кода, блокировками,
race condition,… А разработка самой СУБД приятна и проста.
Но эта же простота накладывает существенное ограничение. Раз внутри процесса всего один рабочий поток, то и использовать он может
не более одного ядра CPU для выполнения запроса — а, значит, скорость работы сервера впрямую зависит от частоты и архитектуры отдельного ядра.
В наш век закончившейся «гонки мегагерцев» и победивших многоядерных и многопроцессорных систем такое поведение является непозволительной роскошью и расточительностью. Поэтому, начиная с версии PostgreSQL 9.6, при отработке запроса
часть операций может выполняться несколькими процессами одновременно.
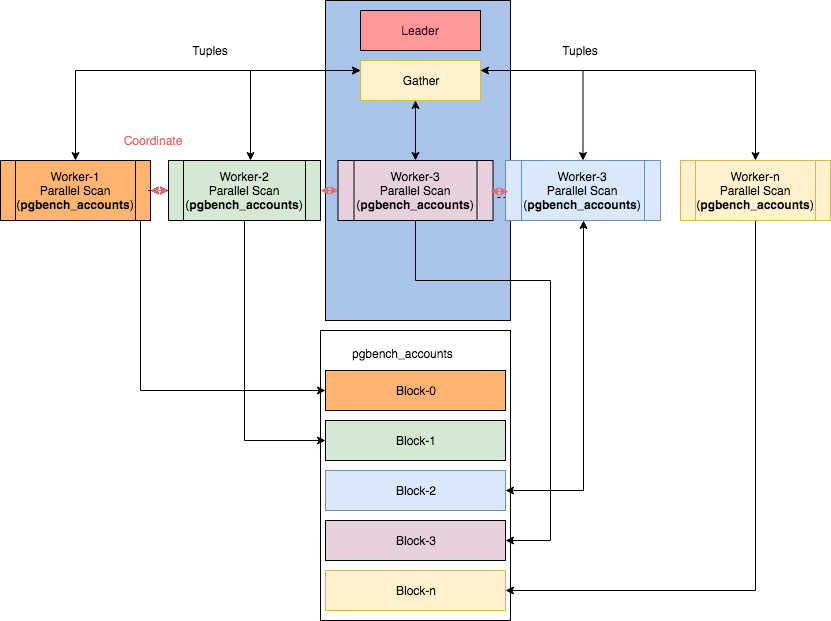
Со схемами работы некоторых параллельных узлов можно ознакомиться в статье «Parallelism in PostgreSQL» by Ibrar Ahmed, откуда взято и это изображение.
Правда, читать планы в этом случае становится… нетривиально.