
Изменение климата: анализируем температуру в разных городах за последние 100 лет
4 мин
Туториал
Привет, Хабр.
Про изменение климата сейчас не говорит только ленивый. И случайно найдя неплохой сайт с историческими данными, стало интересно проверить — как же реально менялась температура с годами. Для теста мы возьмем данные с нескольких городов и проанализируем их с помощью Pandas и Matplotlib. Заодно выясним, действительно ли челябинские морозы настолько суровы, и где теплее, в Москве или Петербурге.

Также обнаружилось еще несколько любопытных закономерностей. Кому интересно узнать подробности, прошу под кат.
Про изменение климата сейчас не говорит только ленивый. И случайно найдя неплохой сайт с историческими данными, стало интересно проверить — как же реально менялась температура с годами. Для теста мы возьмем данные с нескольких городов и проанализируем их с помощью Pandas и Matplotlib. Заодно выясним, действительно ли челябинские морозы настолько суровы, и где теплее, в Москве или Петербурге.
Также обнаружилось еще несколько любопытных закономерностей. Кому интересно узнать подробности, прошу под кат.

 иллюстрации за исключением схемы устройства взяты из
иллюстрации за исключением схемы устройства взяты из 

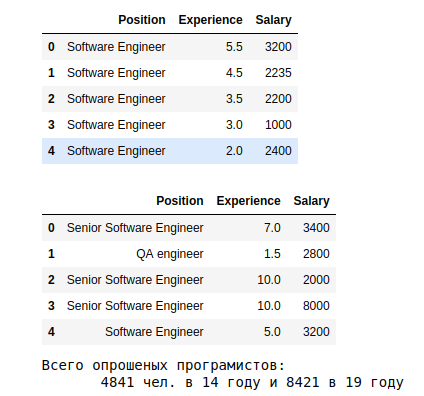



![Как собрать когорты пользователей в виде графиков в Grafana [+docker-образ с примером]](https://habrastorage.org/webt/ug/t6/qv/ugt6qvozluprzn95q1c5gac-gh0.png)

 В Калифорнии в возрасте 74 лет умер американский нобелевский лауреат по химии Кэри Муллис. По словам его супруги, смерть наступила 7 августа. Причина — сердечная и дыхательная недостаточность из-за пневмонии.
В Калифорнии в возрасте 74 лет умер американский нобелевский лауреат по химии Кэри Муллис. По словам его супруги, смерть наступила 7 августа. Причина — сердечная и дыхательная недостаточность из-за пневмонии.