Побудительным мотивом к написанию этюда послужила статья «В карантин нагрузка выросла в 5 раз, но мы были готовы». Как Lingualeo переехал на PostgreSQL с 23 млн юзеров. Так же показалось интересной статья опубликованная 4 года назад — Реализация бизнес-логики в MySQL.
Показалось интересным то, что одна и та же мысль-"реализовать бизнес-логику в БД".

пришла в голову не только мне одному.
Также на будущее хотелось сохранить, для себя в первую очередь, интересные наработки возникшие по ходу реализации. Особенно учитывая то, что относительно недавно было принято стратегическое решение о смене архитектуры и переносе бизнес-логики на уровень backend. Так, что все, что было наработано, скоро никому не понадобится и никому будет не интересно.
Описанные методы не являются каким то открытием и исключительным know how, все по классике и было реализовано неоднократно (я например подобный подход применил 20 лет назад на Oracle).Просто решил собрал все в одном месте. Вдруг кому пригодится. Как показала практика — довольно часто одна и та же идея приходит независимо разным людям. Да и для себя оставить на память, полезно.
Показалось интересным то, что одна и та же мысль-"реализовать бизнес-логику в БД".
пришла в голову не только мне одному.
Также на будущее хотелось сохранить, для себя в первую очередь, интересные наработки возникшие по ходу реализации. Особенно учитывая то, что относительно недавно было принято стратегическое решение о смене архитектуры и переносе бизнес-логики на уровень backend. Так, что все, что было наработано, скоро никому не понадобится и никому будет не интересно.
Описанные методы не являются каким то открытием и исключительным know how, все по классике и было реализовано неоднократно (я например подобный подход применил 20 лет назад на Oracle).Просто решил собрал все в одном месте. Вдруг кому пригодится. Как показала практика — довольно часто одна и та же идея приходит независимо разным людям. Да и для себя оставить на память, полезно.
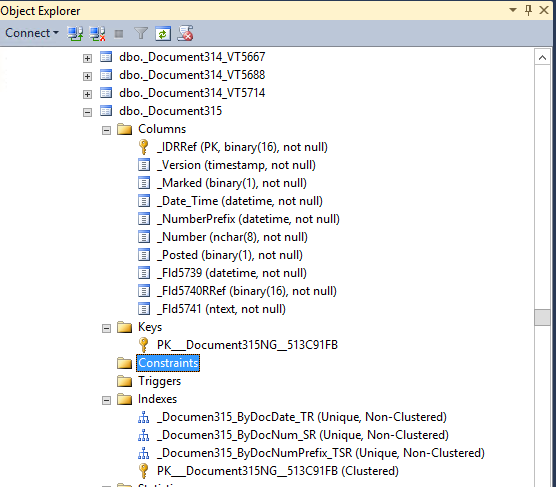
Конечно, же ничто в этом мире не совершенно, ошибки и опечатки к сожалению возможны. Критика и замечания всячески приветствуются и ожидаются.И еще одна маленькая деталь — конкретные детали реализации опущены. Все таки всё используется пока в реально работающем проекте. Так, что статья как этюд и описание общей концепции, не более того. Надеюсь для понятия общей картины, деталей достаточно.