Решил я поискать работы Sci-Fi-художников прошлого и настоящего, которые рисовали реактивные ранцы. Нашел группу в ВК «Музей будущего», а там — 16 000 фотографий. Пришлось пересмотреть все вручную, навыбирал несколько десятков с джетпакоподбными аппаратами (
см. подборку под катом), а потом задумался, а как же бедные фотографы? Или прочие товарищи, которые работают с тоннами фото/аудио/видео, да еще не в одиночку, а командами, удаленно и пр и пр.
Поспрашивал у знакомых фотографов — они пользуются эдаким миксом лайтрума, гуглдрайва и съемных жестких дисков. Говорят, полный ад.
Поинтересовался у знакомой, которая коммьюнити-менеджер русскоязычного сообщества игр крупной компании в гейм-индустрии на букву «B». Им нужно каталогизировать и искать среди огромного количества аудио- и видео-материалов. Создают много трейлеров к видео, game captures, звуковых эффектов, музыки. Куча файлов, относящихся к разным проектам, которые нужно побороть для дальнейшего кросс-проектного поиска. Не столько важно быстро находить, сколько находить в принципе.
Спросил ещё у архитекторов, у которых в базе 120 000 фоток объектов, как они живут с этим.
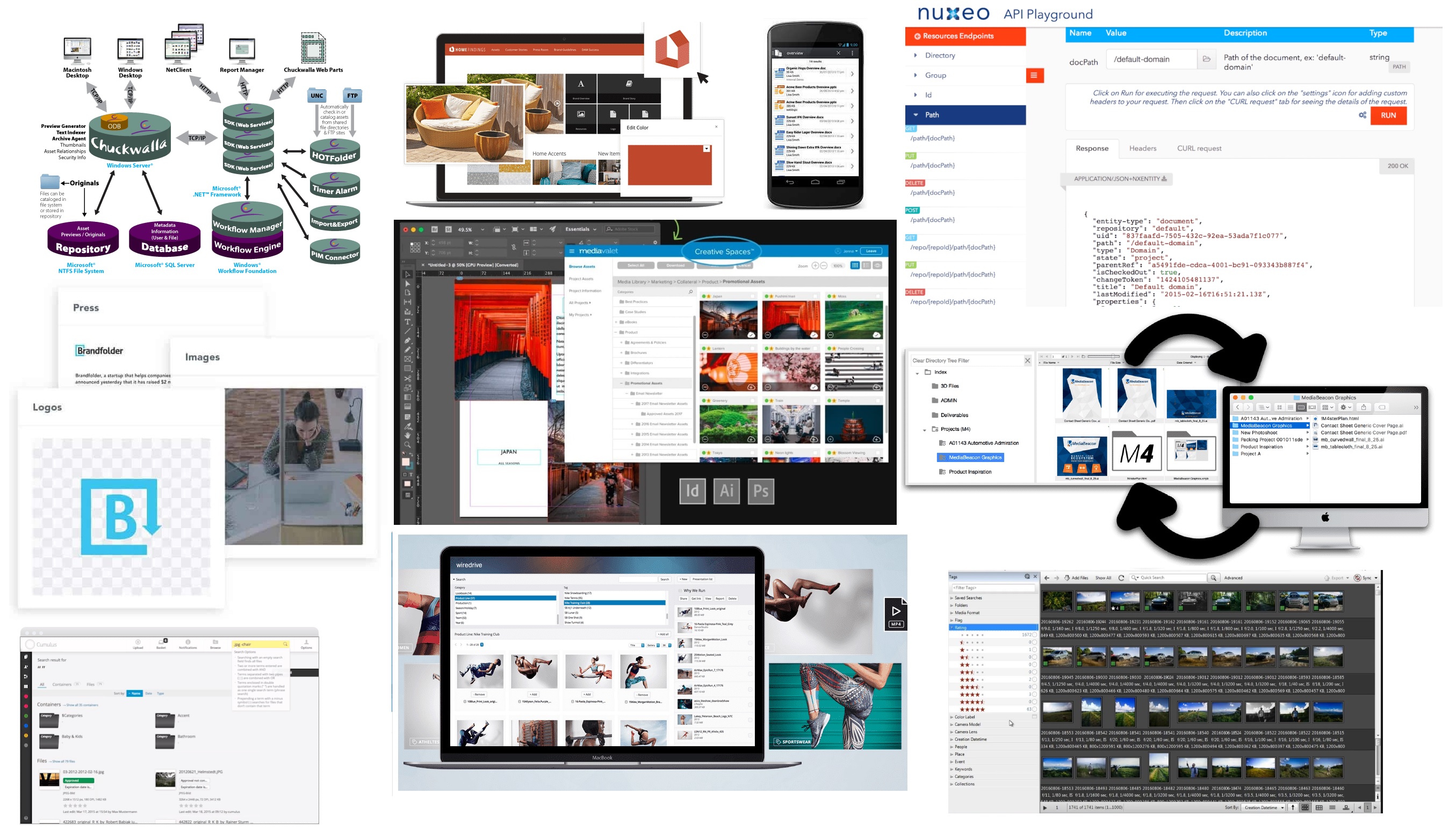
Оказывается вся эта область называется digital asset management.
Вот список с рейтингами 30+ решений для управления цифровыми ресурсами (англ).