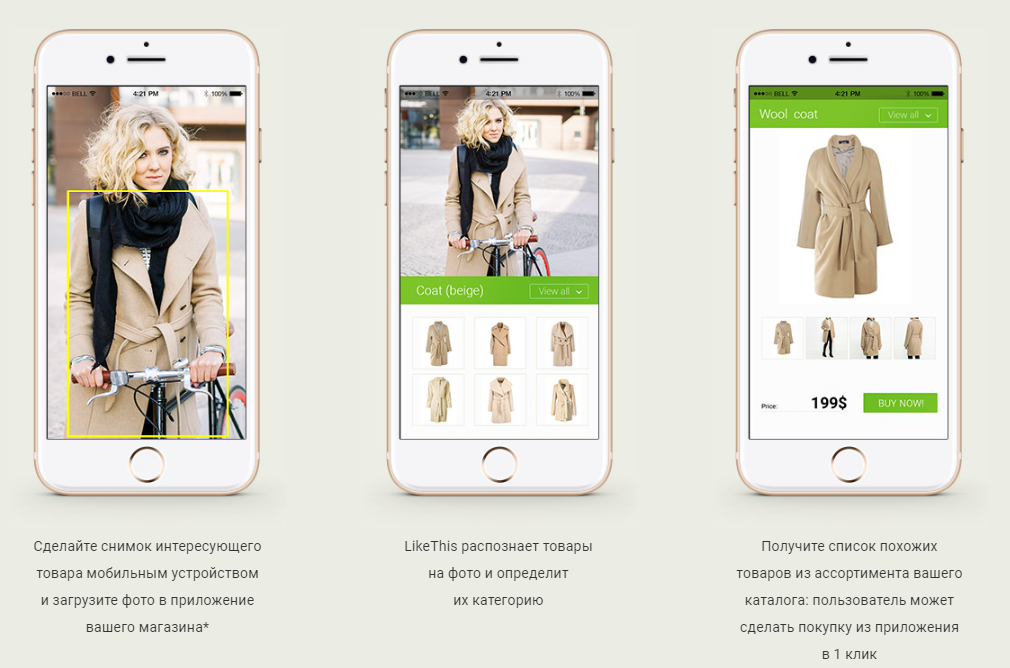
В этой статье я хочу рассказать о том, как мы создали систему поиска похожей одежды (точнее одежды, обуви и сумок) по фотографии. То есть, выражаясь бизнес-терминами, рекомендательный сервис на основе нейронных сетей.
Как и большинство современных IT-решений, можно сравнить разработку нашей системы со сборкой конструктора Lego, когда мы берем много маленьких деталек, инструкцию и создаем из этого готовую модель. Вот такую инструкцию: какие детали взять и как их применить для того, чтобы ваша GPU смогла подбирать похожие товары по фотографии, — вы и найдете в этой статье.
Из каких деталей построена наша система:
- детектор и классификатор одежды, обуви и сумок на изображениях;
- краулер, индексатор или модуль работы с электронными каталогами магазинов;
- модуль поиска похожих изображений;
- JSON-API для удобного взаимодействия с любым устройством и сервисом;
- веб-интерфейс или мобильное приложение для просмотра результатов.
В конце статьи будут описаны все “грабли”, на которые мы наступили во время разработки и рекомендации, как их нейтрализовать.
Постановка задачи и создание рубрикатора
Задача и основной use-case системы звучит довольно просто и понятно:
- пользователь подает на вход (например, посредством мобильного приложения) фотографию, на которой присутствуют предметы одежды и/или сумки и/или обувь;
- система определяет (детектирует) все эти предметы;
- находит к каждому из них максимально похожие (релевантные) товары в реальных интернет-магазинах;
- выдает пользователю товары с возможностью перейти на конкретную страницу товара для покупки.
Говоря проще, цель нашей системы — ответить на знаменитый вопрос: “А у вас нет такого же, только с перламутровыми пуговицами?”










 Я уже делал на Хабре
Я уже делал на Хабре 



