Программированию конец?
Средний
27 мин
Мнение
Recovery Mode
Перевод

Данная статья является переводом видеоролика с канала Мэтта Вулфи, который в основном посвящен теме искусственного интеллекта.
В данном видео Мэтт Вулфи обсуждает вопрос, который волнует многих: сможет ли искусственный интеллект заменить программистов? Он рассматривает текущее состояние дел и будущие возможности ИИ в программировании.
Основные моменты видео:
Разногласия в части темы замены программистов Искусственным Интеллектом.
Автоматизация задач с помощью ИИ: написание и отладка кода.
Влияние ИИ на участие разработчиков в процессе.
Необходимость наличия связующего звена между ИИ и конечными пользователями.
А также много другое и капелька теории!









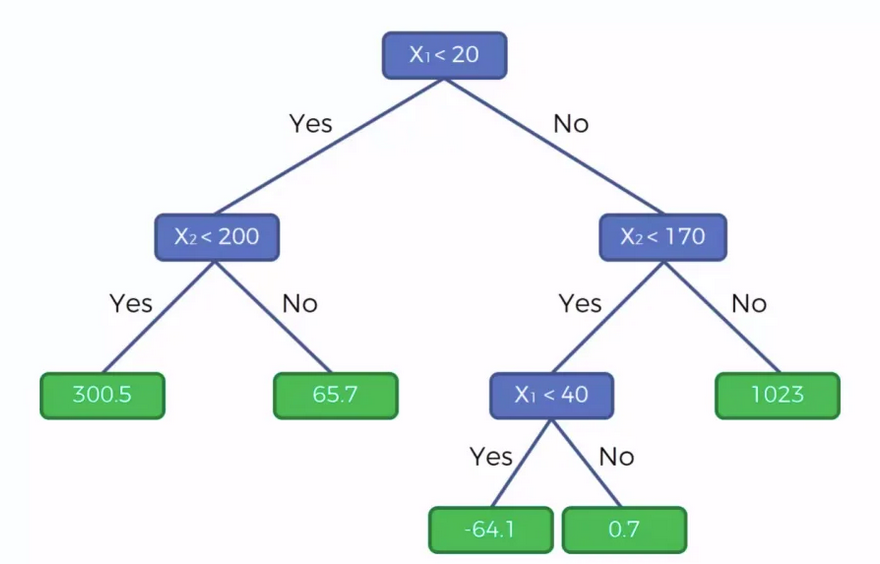

 , дали определения контрольной
, дали определения контрольной  и тестовой
и тестовой  группам. А так же условились, что же такое воздействие
группам. А так же условились, что же такое воздействие на пользователя
на пользователя  .
. и
и  из
из  и
и  соответственно, объединить их в одно подмножество, чтобы в дальнейшем можно было сделать допущение, что
соответственно, объединить их в одно подмножество, чтобы в дальнейшем можно было сделать допущение, что  и
и  представляют из себя уже единого синтетического пользователя
представляют из себя уже единого синтетического пользователя  . Где пользователь
. Где пользователь  вместе с его параметрами
вместе с его параметрами  выполняет роль пользователя
выполняет роль пользователя , с которым мы не взаимодействовали
, с которым мы не взаимодействовали  , а пользователь
, а пользователь  вместе с его параметрами
вместе с его параметрами  выполняет роль пользователя
выполняет роль пользователя  , с которым мы провзаимодействовали
, с которым мы провзаимодействовали  .
.