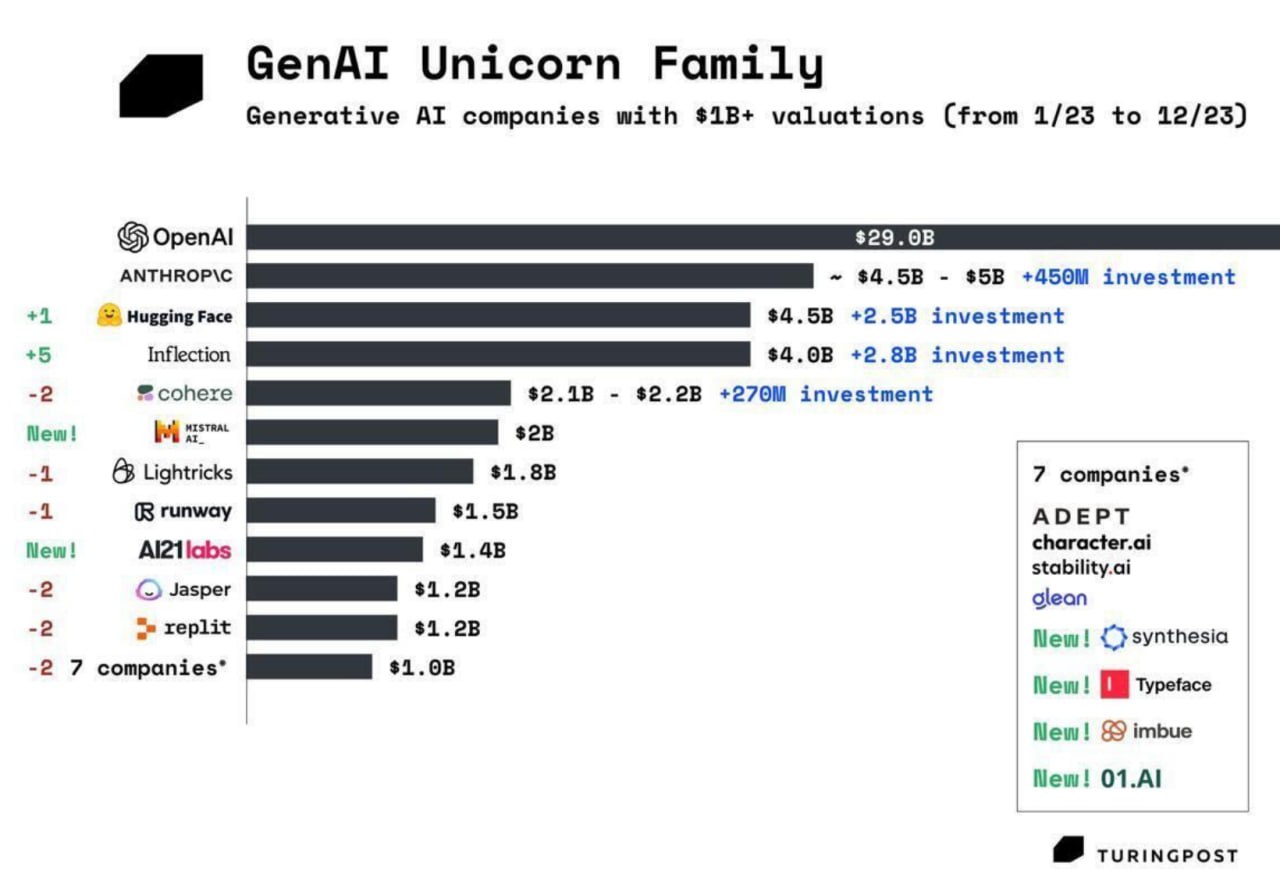
Одно из самых прикладных применений языковых моделей (LLM) - это ответы на вопросы по документу/тексту/договорам. Языковая модель имеет сильную общую логику, а релевантные знания получаются из word, pdf, txt и других источников.
Обычно релевантные тексты раскиданы в разных местах, их много и они плохо структурированы. Одна из проблем на пути построения хорошего RAG - нахождение релевантных частей текста под заданный пользователем вопрос.
Еще В. Маяковский писал: "Изводишь единого слова ради, тысячи тонн словесной руды." Примерно это же самое делают би-энкодеры и кросс-энкодеры в рамках RAG, ищут самые важные и полезные слова в бесконечных тоннах текста.
В статье мы посмотрим на способы нахождения релевантных текстов, увидим проблемы, которые в связи с этим возникают. Попытаемся их решить.
Главное - мы натренируем свой кросс-энкодер на русском языке, что служит важным шагом на пути улучшения качества Retrieval Augmented Generation (RAG). Тренировка будет проходит новейшим передовым способом. Схематично он изображен на меме справа)