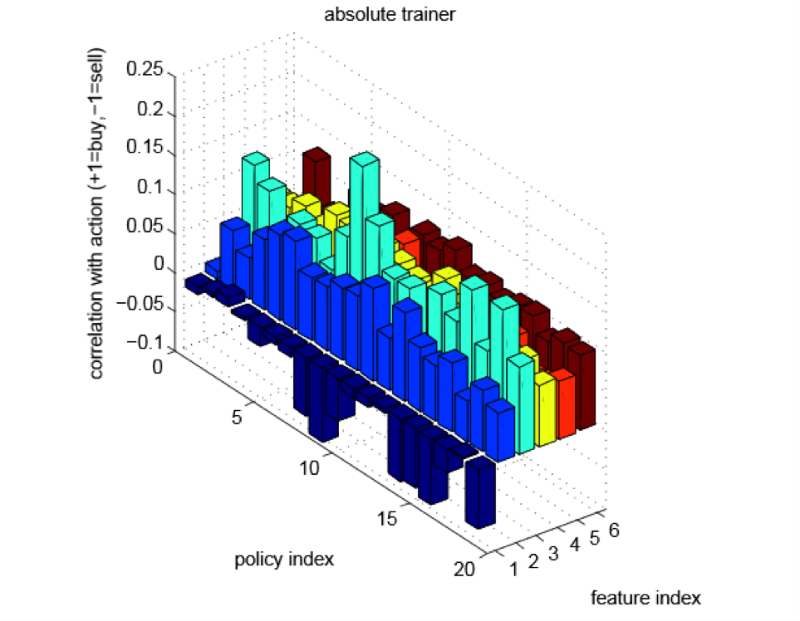
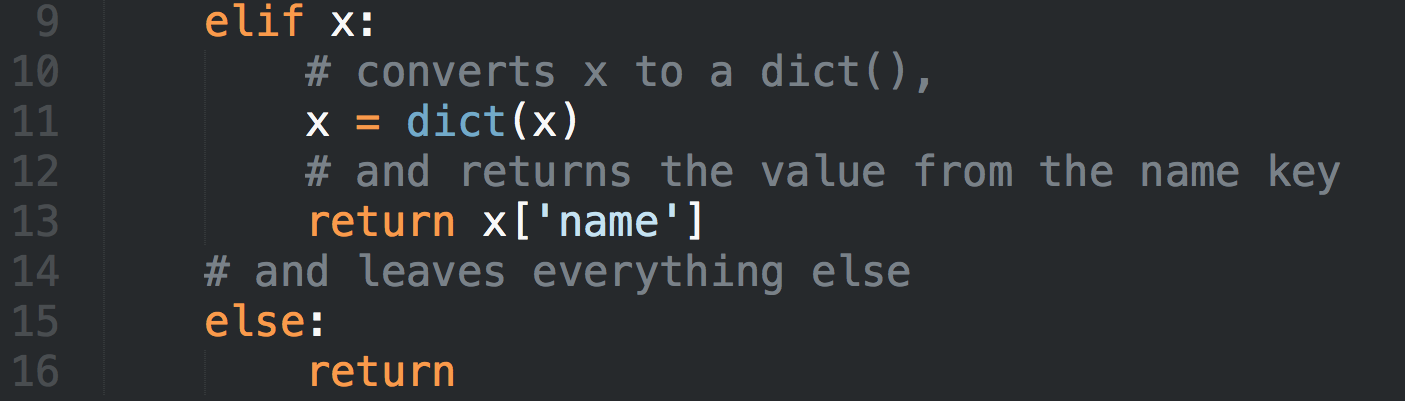
Добрый день, коллеги,
Продолжая ранее опубликованную статью про высокоточную систему навигации (+-2см) внутри помещений, мы хотели бы показать, как простой робот на ее основе может кататься по какому угодно сложному маршруту совершенно автономно.
На видео ниже мы повесили мобильный маячок на простого робота и отправили его гулять по маршруту в виде восьмерки, чем он может и заниматься часами:
Или можно его отправить бегать по прямоугольнику:
Продолжая ранее опубликованную статью про высокоточную систему навигации (+-2см) внутри помещений, мы хотели бы показать, как простой робот на ее основе может кататься по какому угодно сложному маршруту совершенно автономно.
На видео ниже мы повесили мобильный маячок на простого робота и отправили его гулять по маршруту в виде восьмерки, чем он может и заниматься часами:
Или можно его отправить бегать по прямоугольнику:





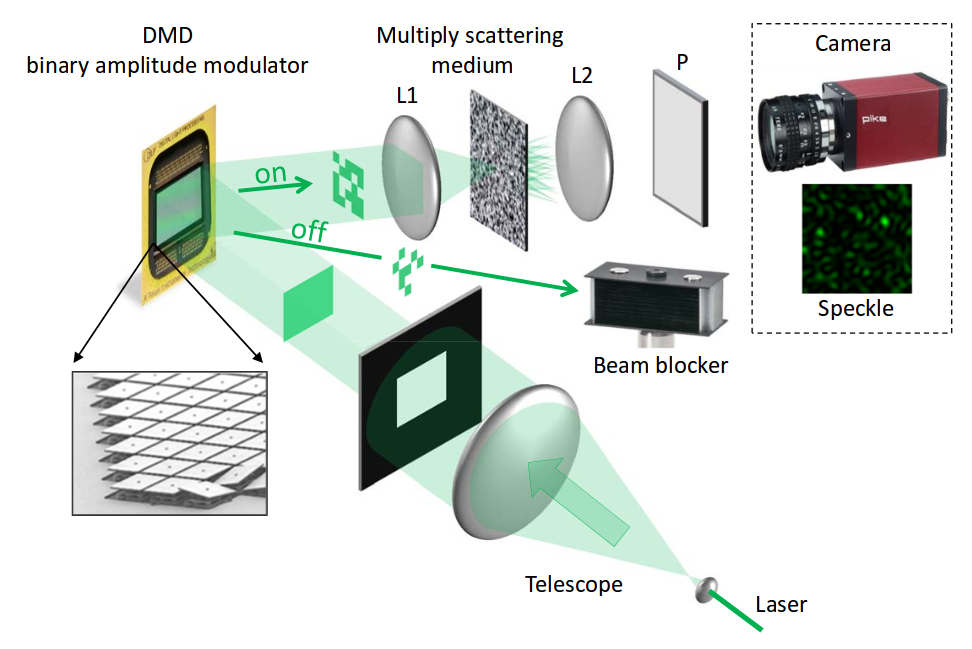


 Как вы знаете, ABBYY занимается разработкой технологии анализа естественных языков Compreno. Сейчас система работает на английском и русском языках, и активно используется во многих проектах. Однако изначально сама технология была задумана как многоязычная, поэтому мы много внимания уделяем и «обучению» другим иностранным языкам. И тут можно провести некоторую аналогию с человеком: после изучения одного иностранного языка другие даются легче. В частности, сейчас мы добавляем в технологию немецкий язык и параллельно исследуем возможности рынка – есть ли интерес к этому направлению. Сразу оговоримся – пока речь о продуктах, поддерживающих немецкий, не идёт, мы в самом начале пути.
Как вы знаете, ABBYY занимается разработкой технологии анализа естественных языков Compreno. Сейчас система работает на английском и русском языках, и активно используется во многих проектах. Однако изначально сама технология была задумана как многоязычная, поэтому мы много внимания уделяем и «обучению» другим иностранным языкам. И тут можно провести некоторую аналогию с человеком: после изучения одного иностранного языка другие даются легче. В частности, сейчас мы добавляем в технологию немецкий язык и параллельно исследуем возможности рынка – есть ли интерес к этому направлению. Сразу оговоримся – пока речь о продуктах, поддерживающих немецкий, не идёт, мы в самом начале пути.