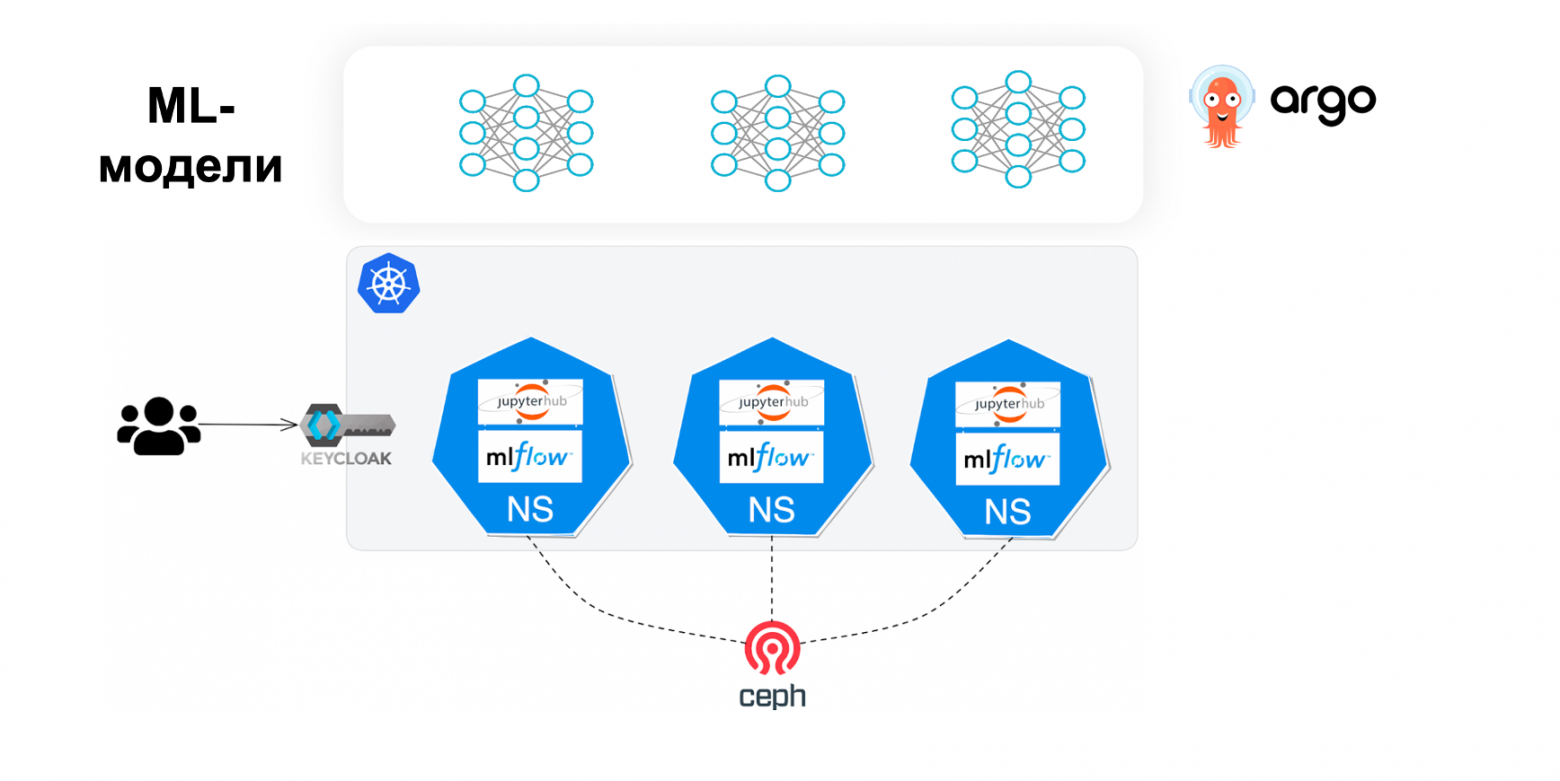
Современный мир сложно представить без технологий, которые его наполняют. Некоторые из них малозаметны, тогда как другие приковывают к себе внимание буквально всех и каждого. Одной из таких технологий является искусственный интеллект. Данное направление объединяет в себе множество отдельных, но взаимосвязанных ветвей, одной из которых является генеративный ИИ. Основная функция такого ИИ заключается в генерации текстов, изображений или других медиаданных в ответ на запрос человека. Говоря о таком взаимоотношении между человеком и машиной, первым на ум приходит крайне популярный ChatGPT. Но его возможности хоть и велики, но не безграничны. Ученые из Школы инженерии и прикладных наук Пенсильванского университета (США) разработали систему, способную в ответ на текстовый запрос пользователя генерировать трехмерную виртуальную среду, как это делала голопалуба в сериале «Звездный путь: Следующее поколение». Как работает данная система, насколько обширны ее возможности, и где она может быть полезна? Ответы на эти вопросы мы найдем в докладе ученых.