
Пересказ грамматики Ложбана или что мне удалось усвоить
Ложбан — искусственный человеческий язык, созданный на основе Логланга в 1987 году Группой логического языка (The Logical Language Group). Лицензионно-открыт и свободен. Основан на логике предикатов. Имеет описание в формате YACC и EBNF.
Алфавит
a, b, d, f, g, i, k, l, m, n, o, p, r, s, t, v, z — читаются как в английском
h, w, q — нет в алфавите
e — читается как русская Э
u — читается как русская У
c — читается как русская Ш. Но ci — произносится как «щи».
х — читается как русская Х (!)
j — читается как русская Ж
tc — читается как русская Ч
y — это шва и произноситься как безударная Ы. Например cy — произносится как «шы».
' — просто разделитель наподобие наших Ь, Ъ знаков (в транскрипции заменяется на h).
. — пауза в произношении.
Числительные
0 — no, 1 — pa, 2 — re, 3 — ci, 4 — vo, 5 — mu, 6 — ха, 7 — ze, 8 — bi, 9 — so
pi — десятичная точка
Например:
pa re ci pi vo mu — 123,45
pa no no — 100
 Недавно завершился «
Недавно завершился « Источник картинки: Собственное творчество от команды Антиплагиата
Источник картинки: Собственное творчество от команды Антиплагиата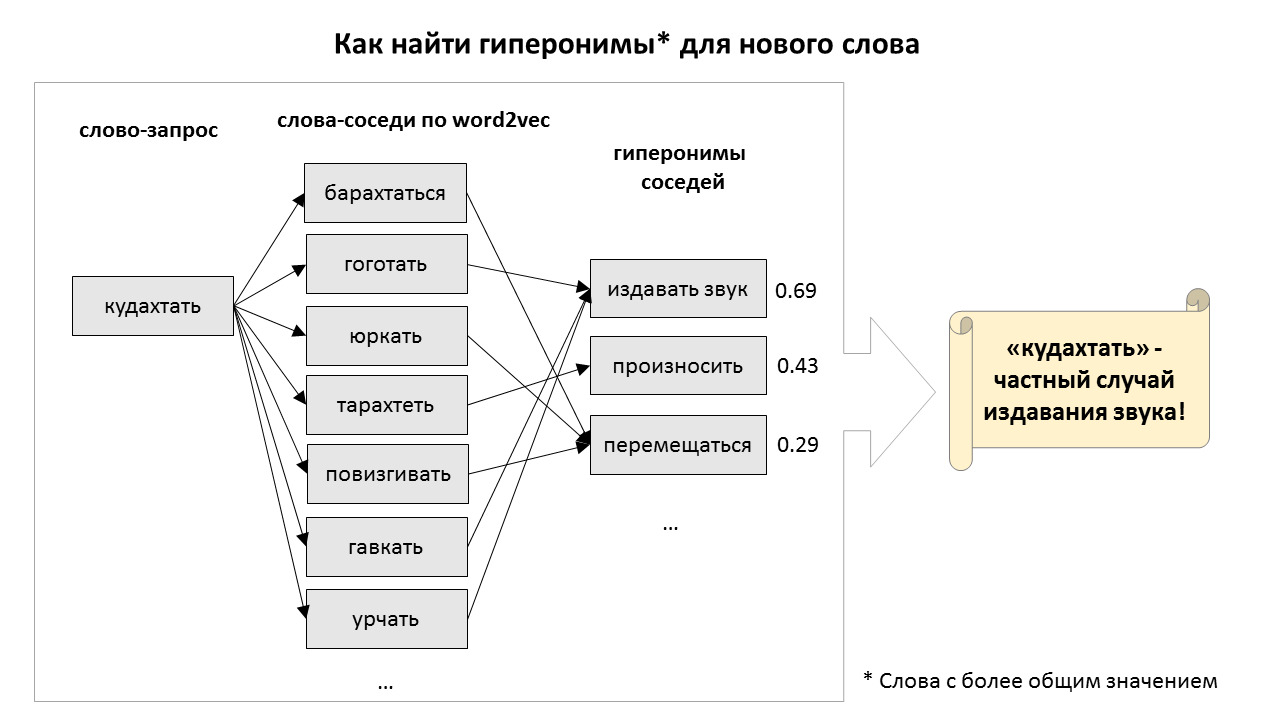
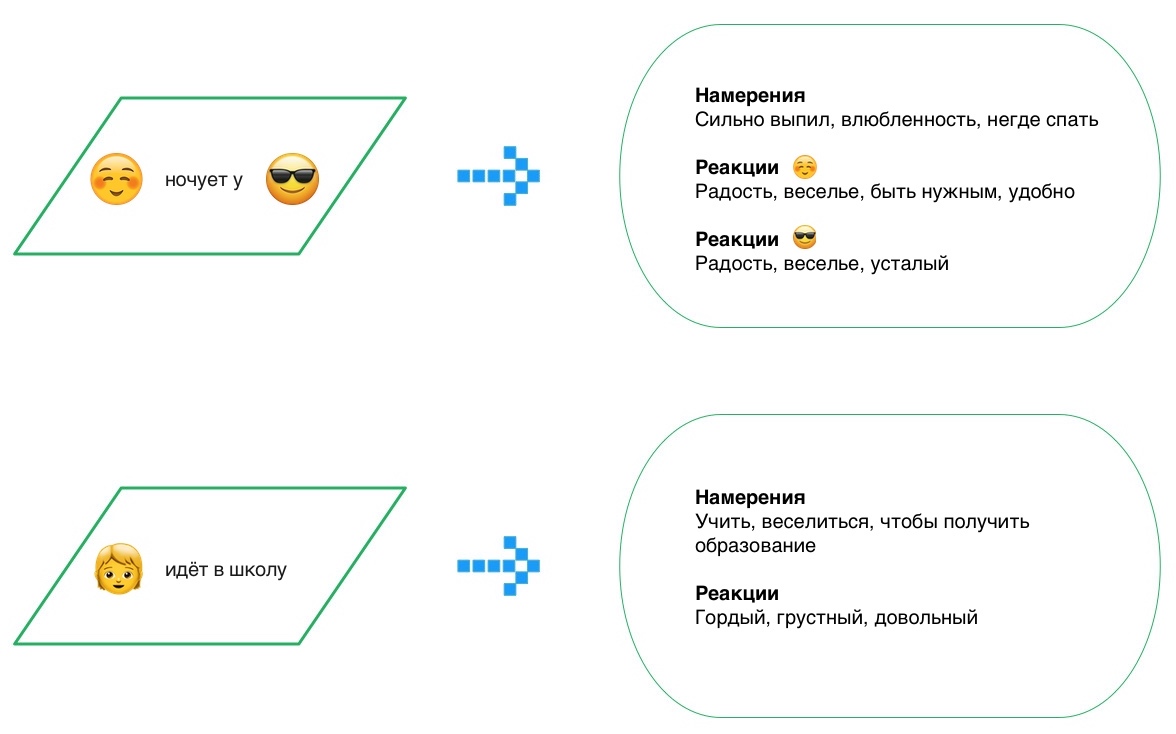



 Текущая ситуация в мире не повод останавливать диалог, особенно если его можно вести онлайн. С 17 по 20 июня состоится 26-ая Международная научная конференция по компьютерной лингвистике и интеллектуальным технологиям «
Текущая ситуация в мире не повод останавливать диалог, особенно если его можно вести онлайн. С 17 по 20 июня состоится 26-ая Международная научная конференция по компьютерной лингвистике и интеллектуальным технологиям «

 Прошлогоднюю статью
Прошлогоднюю статью