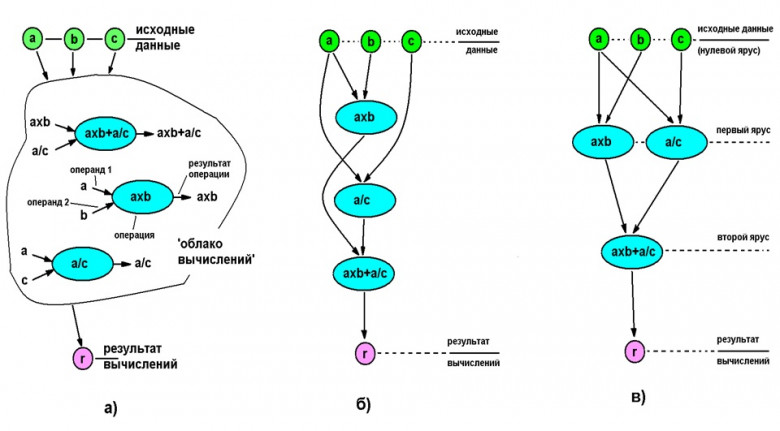
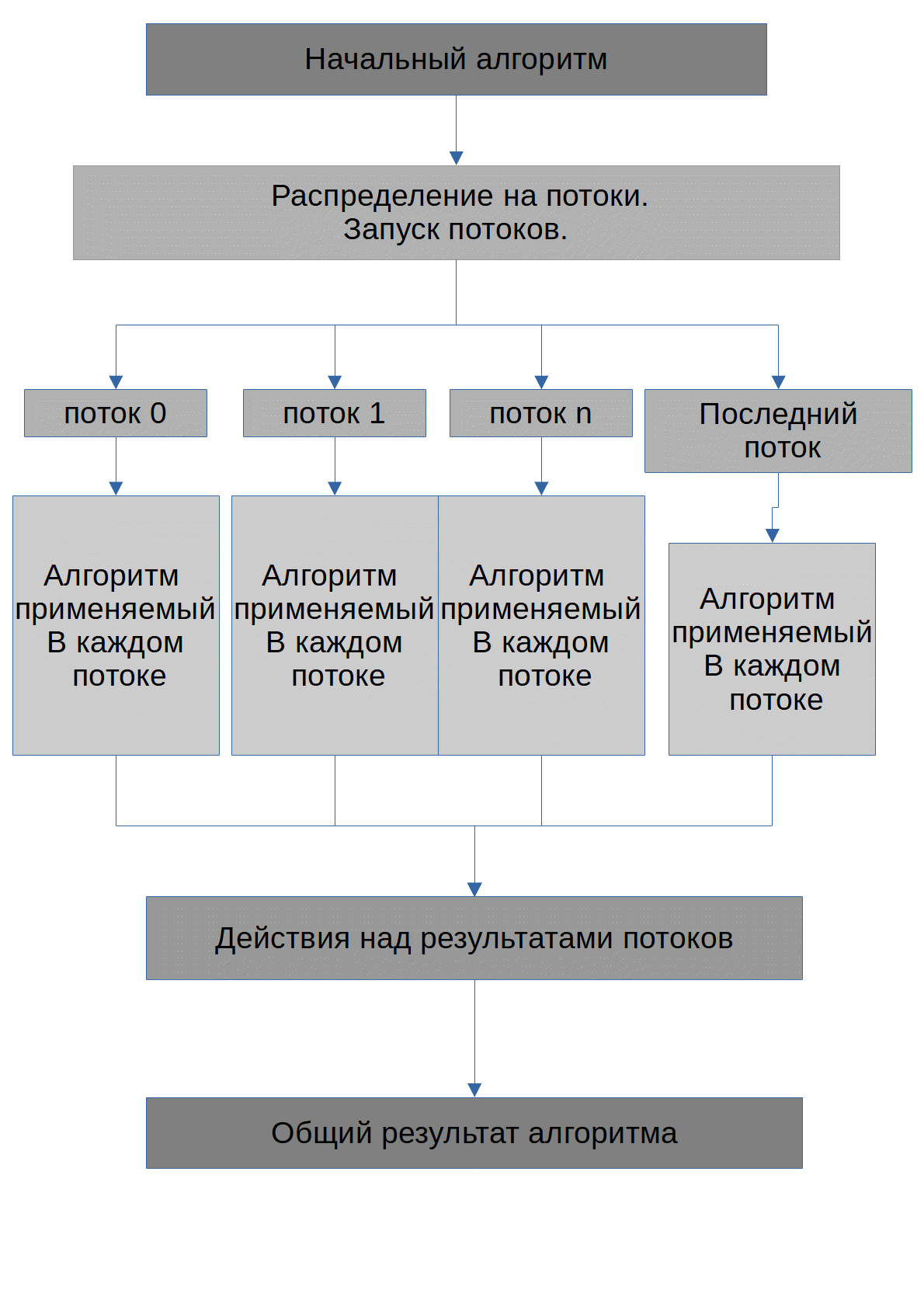
Это расшифровка-перевод доклада Саши Гольдштейна, признанного лучшим на конференции DotNext 2016 Piter. С годами этот доклад стал лишь актуальнее прежнего: появление Mac на ARM-процессорах — еще один пример, почему разработчикам сегодня нужно думать не только о x86-архитектуре.

Речь пойдет о проблемах, с которыми вы можете столкнуться при написании многопоточного кода, если вы думаете, что достаточно умны, чтоб спроектировать свои собственные механизмы синхронизации.
То, что подходит процессорам Intel на архитектурах x86 и x86-64, может не подойти другой архитектуре. Как только вы перенесете свой код на другой процессор, например, на ARM для iPhone и Android, есть вероятность, что он перестанет работать как надо. Проблемы могут быть как очевидными (воспроизводиться с первого-второго раза), так и не очень (возникать только раз в миллион итераций). Вполне вероятно, что такие баги могут добраться до продакшна. Сегодня .NET и, конечно, C++ можно использовать не только на Windows и Intel, но и на других платформах, так что доклад будет полезен многим разработчикам.
Дисклеймер: статья предназначена для продвинутых читателей. Смотрите на свой страх и риск. За частое упоминание барьеров памяти и изменения порядка исполнения инструкций она получила возрастное ограничение 18+.