
Как с нуля разработать систему аналитики для телеграм бота?
5 мин

Всем привет! Мы команда Dev’s Battle. В этом посте расскажем о том, как мы создавали для нашего продукта (MMO RPG игра в телеграм) собственную систему аналитики
Всем привет! Мы команда Dev’s Battle. В этом посте расскажем о том, как мы создавали для нашего продукта (MMO RPG игра в телеграм) собственную систему аналитики

Этот материал посвящен сервису Xalq Nazorati (Народный Контроль) — с ним люди могут пожаловаться на нерабочий лифт, яму на дороге, сломанный светофор или стертую дорожную разметку. В статье расскажем, с чего мы начинали проект, какие ошибки допускали, как их исправляли и где в итоге оказались.
Чтобы контролировать работу сервиса и обеспечить реальное решение проблем, мы разработали рейтинг районов города, тем самым мотивируя чиновников не отмахиваться от проблем.
Чтобы лучше обозначать раскрытие темы, используем индикатор из хорошо знакомой многим игры. Так интереснее.
Резюме
Сегодня в сервис Народный Контроль уже поступило более 28 тыс. обращений от горожан — чаще всего люди жалуются на проблемы на дорогах, ЖКХ и экологические проблемы.
88% всех обращений были в итоге решены.

Postgres - один из крупнейших open source проектов. Он создавался многие года. Кодовая база накопилась огромная. Мне, как программисту, всегда было интересно как он работает под капотом. Но не про SQL пойдет речь, а про язык на котором он написан. Про C.
С общей архитектурой можно ознакомиться здесь
Для начала поймем, что происходит до входа в главный цикл сервера.
Не секрет, что тема перехода в IT-сфере на технологии, не требующие дорогостоящего лицензирования становится всё более актуальной. В то же время, очевидно и стремление компаний попасть в Реестр отечественного ПО, чтобы получить разного рода преференции для себя и своих сотрудников.
С точки зрения обновления технологического стека, мы воспользовались методическими рекомендациями Реестра отечественного ПО и приняли решение о переводе наших проектов на технологии со свободными лицензиями, в частности .NET 6 и PostgreSQL. Это открыло путь как к оптимизации производительности приложений и уменьшению расходов на лицензирование, так и добавлению решений компании в реестр.
В данной статье предлагаю рассмотреть путь по миграции географического микросервиса с MS SQL на PostgreSQL с фокусом на пространственные (spatial) типы данных.
Вопрос стоимости лицензий и непосредственного сравнения MS SQL vs PostgreSQL опустим, т.к. эта тема весьма хорошо раскрыта в DotNext-докладе моего коллеги, Стаса Флусова. Рекомендую к просмотру!

Сегодня СУБД PostgreSQL является одной из самых известных и популярных систем управления баз данными в мире. Открытый исходный код, отсутствие платы за использование, контроль целостности, репликация – это далеко не все преимущества данной СУБД. В современных реалиях, когда тема импортозамещения особенно актуальна, PostgreSQL может оказаться подходящим вариантом.
Обычно PostgreSQL разворачивают в качестве кластера – системы, которая состоит из нескольких связанных между собой компьютеров (серверов) с целью обеспечения отказоустойчивости.
Как правило при развертывании кластеров PostgreSQL используют сторонние инструменты такие как Patroni, stolon, repmgr.
В статье будет описана установка кластера PostgreSQL с помощью Ansible – инструмента, предназначенного для автоматизации настройки и развертывания программного обеспечения, а также инструмента repmgr, предназначенного для управления репликами и отказоустойчивостью в кластерах PostgreSQL.


Как:
1. тестировать на продуктивных данных и не бояться
2. получить 100 копий продуктивной БД и не создавать 100 серверов
3. узнать какой будет план запроса на продуктиве
4. дать каждому разработчику свою БД с данными и не разориться на оплате дисков
Если вам это нужно и у вас PostgreSQL, то эта статья для вас.

Мне стало интересно разобраться, как PostgreSQL хранит данные на диске, и в процессе своего исследования я обнаружил несколько интересных фактов, которыми хочу с вами поделиться.
Мы будем рассматривать только файлы кучи (heap). Heap-файл — это просто файл записей. Не путайте heap-файл с heap-памятью. Хотя их использование очень похоже: хранение динамических данных.

Навскидку многим кажется, что они знакомы с поведением NULL-значений в PostgreSQL, однако иногда неопределённые значения преподносят сюрпризы. Предлагаем вашему вниманию расшифровку доклада Алексея Борщева с PGConf.Russia 2022 — он был полностью посвящён особенностям NULL-значений в Postgres.
NULL простыми словами
Что такое SQL база данных? Согласно одному из определений, это просто набор взаимосвязанных таблиц. А что такое NULL? Обратимся к простому бытовому примеру: все мы задаём друг другу дежурный вопрос: «Как дела?». Часто мы получаем в ответ: «Да ничего...» Вот это «ничего» нам и нужно положить в базу данных — NULL, неопределённое, некорректное или неизвестное значение.
PostgreSQL 15 уже вышел официально. И в сети появилось множество информации о новинках версии.
А мы продолжаем знакомить с новинками будущей 16-й версии. В начале октября завершился второй коммитфест и есть что обсудить.
Самое интересное из первого, июльского, коммитфеста можно прочитать в предыдущей статье серии: 2022-07.

Меня зовут Азат Якупов, я люблю данные и люблю использовать их в разных задачах. Сегодня хочу поделиться своим опытом относительно B-Tree индексов в PostgreSQL. Рассмотрим их топологию, синтаксис, функциональные B-Tree индексы, условные B-Tree индексы и включенные B-Tree индексы.

Наверняка, многие из вас пользуются explain.tensor.ru - нашим сервисом визуализации PostgreSQL-планов или уже даже развернули его на своей площадке. Но визуализация конкретного плана - это лишь небольшая помощь разработчику, поэтому в "Тензоре" мы создали сервис, который позволяет увидеть сразу многие аспекты работы сервера: медленные или гигантские запросы, возникающие блокировки и ошибки, частоту и результаты проходов [auto]VACUUM/ANALYZE.
И сегодня мы, наконец, готовы представить вам демо-режим этого сервиса, куда вы самостоятельно можете загрузить лог своего PostgreSQL-сервера и наглядно увидеть, чем он у вас занимается.

В этой статье рассматриваются преимущества такого редко используемого и, на мой взгляд, незаслуженно обойденного вниманием типа данных, как диапазон. Мы сначала спроектируем структуру базы для хранения коэффициента возраст-стаж при расчете стоимости полиса ОСАГО в рамках привычной многим MySQL. Затем перепроектируем под PostgreSQL и посмотрим, как выглядят sql запросы в обоих случаях. И в финале сравним, какие преимущества дает нам использование диапазонов.
Заметка адресована как пользователям MySQL, так и пользователям PostgreSQL, которые не работали с таким типом данных в своей практике. Если в вашей предметной области есть работа с диапазонами величин, то этот пост точно для вас.

Свободная СУБД PostgreSQL известна не только как высокопроизводительное решение для выполнения запросов и хранения данных в реляционной модели, но также своим механизмом расширения, который позволяет создавать дополнительные функции, типы данных, индексы и иные структуры данных для разных предметных областей. В этой статье мы рассмотрим некоторые подходы к сохранению и обработки данных астрономических каталогов (альманахов) с использованием возможностей PostgreSQL.

Статей о работе с PostgreSQL и её преимуществах достаточно много, но не всегда из них понятно, как следить за состоянием базы и метриками, влияющими на её оптимальную работу. В статье подробно рассмотрим SQL-запросы, которые помогут вам отслеживать эти показатели и просто могут быть полезны как пользователю.

Сегодня мы с нашими друзьями из Snaplet открываем исходники postgres-wasm — запускаемый в браузере сервер PostgreSQL с полным набором функционала, включая сохранение состояния в браузере, восстановление из pg_dump и логическую репликацию из удалённой базы данных.
Впервые Postgres в браузере запустили в Crunchy Data, их потрясающая версия выложена на HN месяц назад. Вместе со Snaplet мы решили сделать версию с открытым кодом. Посмотрим, как она разрабатывается и какой функционал мы добавили. Подробности — к старту нашего флагманского курса по Data Science.

В наличии была база данных MSSQL (с которой забираем данные), а также PostgreSQL Pro Enterprise 10.3, развернутая на CentOS 7 (на которую импортируем). Ну и полное отсутствие интернета.
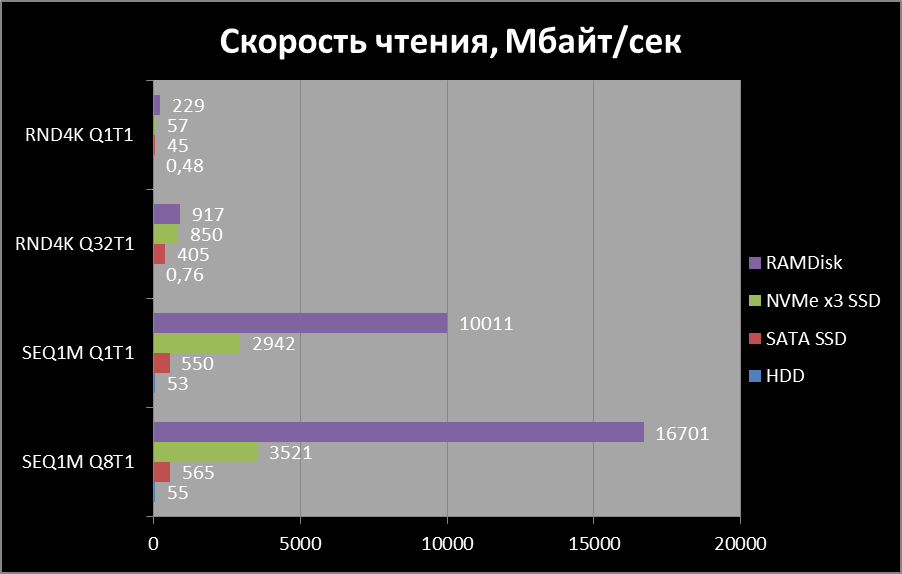
Мне всегда было интересно (и не только мне) есть ли смысл запуска 1С в диске из оперативной памяти, потому что если посмотреть на графики скорости чтения различных типов накопителей, то преимущества очевидны:
На настоящий момент фирма 1С предоставляет возможность установки своего основного программного продукта на ОС Windows, Linux и MacOS (только клиентского приложения).
На официальном портале 1С зарегистрированный пользователь может скачать установочные наборы программ для этих операционных систем. С системами из семейства ОС Windows в данном случае есть достаточно большая ясность, они поддерживаются хорошо, так как имеют наибольшее распространение среди пользователей.
Однако, сама фирма 1С в своей документации и справочных материалах довольно прозрачно намекает, что ОС Windows далеко не единственный вариант установки ПО, в особенности серверной части и что ОС Linux гораздо более предпочтительна в качестве серверной ОС.
На портале 1С мы можем найти разные наборы установочных пакетов для 64-битных и 32-битных систем, для систем из семейства Linux, основанных на deb-пакетах (для системы Debian и её производных — Ubuntu, Mint и других) и основанных на rpm-пакетах (для ОС RedHat и её производных — CentOS, Suse, Fedora и других).
Но при более тщательном изучении документации, можно столкнуться со следующим интересным моментом.
Для того, чтобы установить систему 1С в клиент-серверном варианте, требуется установка не только самого сервера 1С, но и сервера СУБД. Начнём установку именно с этого, так как без работоспособной базы данных устанавливать сервер 1С не имеет смысла.
Вариантов для выбора СУБД весьма немного. Система 1С может работать всего лишь с 4-мя различными СУБД: Microsoft SQL Server, PostgreSQL, IBM DB2 и Oracle Database. Все эти СУБД могут быть установлены на Linux, однако в полноценном варианте Microsoft SQL Server, IBM DB2 и Oracle Database являются платными коммерческими продуктами с немалой стоимостью. А на настоящий момент все эти три корпорации с РФ не работают (Microsoft, IBM, Oracle). У PostgreSQL тоже есть платная версия, но той версии, которая распространяется как свободный и открытый программный продукт, вполне достаточно для работы с сервером 1С. Поэтому при использовании свободной ОС Linux выбор в первую очередь, конечно, падает на PostgreSQL.