
 Разработчики СУБД в силу необходимости, озабочены тем, чтобы данные безопасно попадали в постоянное хранилище. Поэтому, когда сообщество PostgreSQL обнаружило, что то, как ядро обрабатывает ошибки ввода-вывода, может привести к потере данных без каких-либо ошибок, сообщаемых в пользовательское пространство, возникло немало недовольства. Проблема, которая усугубляется тем, что PostgreSQL выполняет буферизованный ввод-вывод, оказывается, не является уникальной для Linux, и ее будет нелегко решить даже там.
Разработчики СУБД в силу необходимости, озабочены тем, чтобы данные безопасно попадали в постоянное хранилище. Поэтому, когда сообщество PostgreSQL обнаружило, что то, как ядро обрабатывает ошибки ввода-вывода, может привести к потере данных без каких-либо ошибок, сообщаемых в пользовательское пространство, возникло немало недовольства. Проблема, которая усугубляется тем, что PostgreSQL выполняет буферизованный ввод-вывод, оказывается, не является уникальной для Linux, и ее будет нелегко решить даже там.Крейг Рингер впервые сообщил о проблеме в список рассылки pgsql-hackers в конце марта. Короче говоря, PostgreSQL предполагает, что успешный вызов
fsync() указывает на то, что все данные, записанные с момента последнего успешного вызова, безопасно перешли в постоянное хранилище. При сбое буферизованной записи ввода-вывода из-за аппаратной ошибки файловые системы реагируют по-разному, но такое поведение обычно включает удаление данных на соответствующих страницах и пометку их как чистых. Поэтому чтение блоков, которые были только что записаны, скорее всего, вернет что-то другое, но не записанные данные.


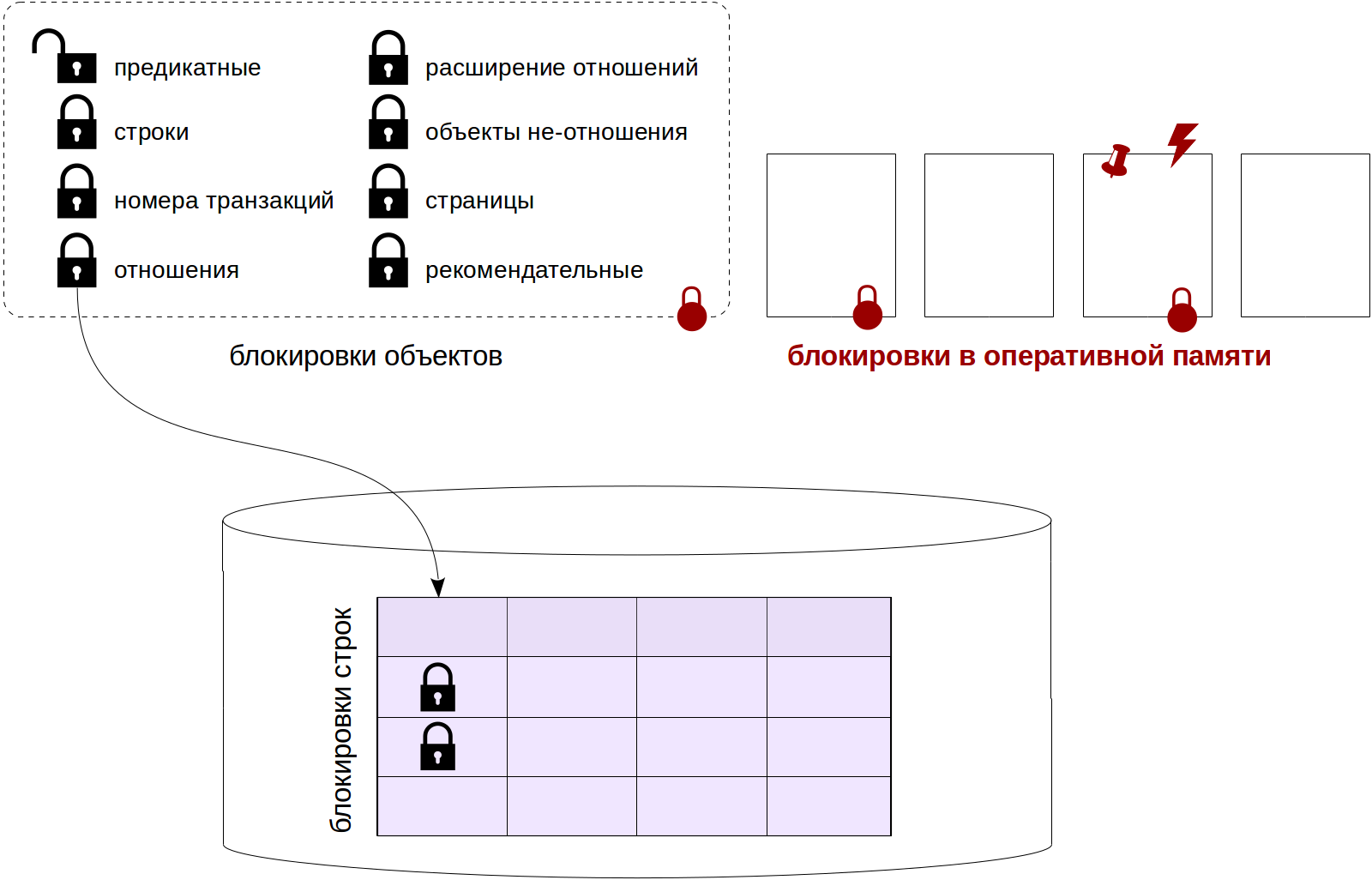


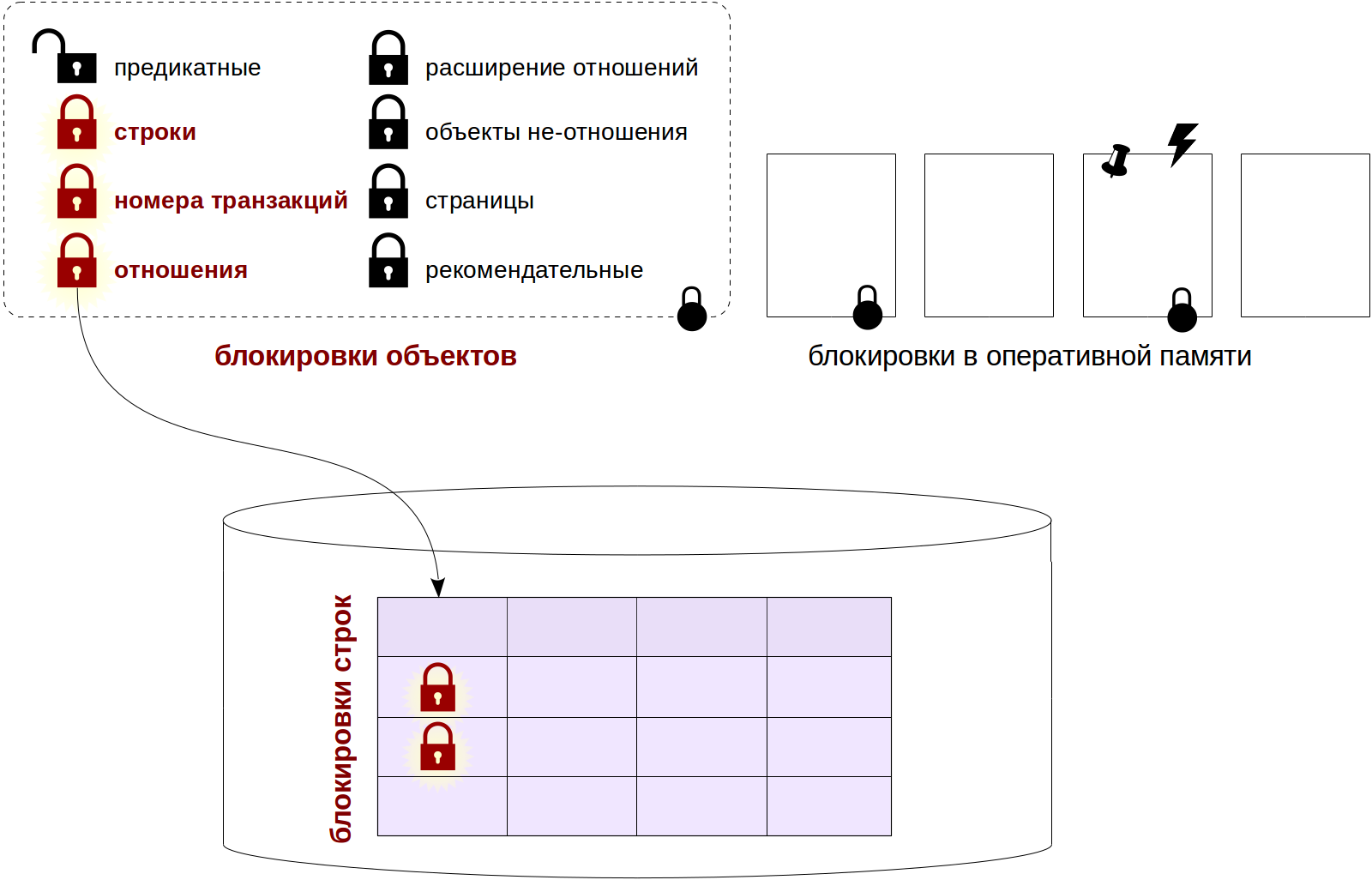

 Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.
Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.