
В этой заметке речь пойдет о том, как писать рекурсивные запросы. Тема эта поднималась не раз и не два, но обычно все ограничивается простыми «деревянными» случаями: спуститься от вершины до листьев, подняться от вершины до корня. Мы же займемся более сложным случаем произвольного графа.
Начнем с того, что повторим теорию (очень кратко, потому что с ней все ясно), а затем поговорим о том, что делать, если непонятно, как подступиться к реальной задаче, или вроде бы понятно, но запрос упорно не хочет работать.
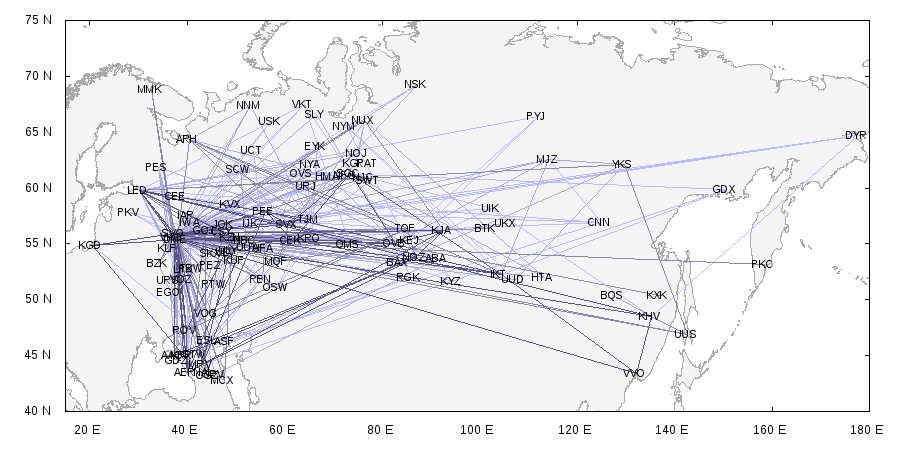
Для упражнения будем использовать демо-базу, подробно описанную ранее, и попробуем написать в ней запрос для поиска кратчайшего пути из одного аэропорта в другой.
Начнем с того, что повторим теорию (очень кратко, потому что с ней все ясно), а затем поговорим о том, что делать, если непонятно, как подступиться к реальной задаче, или вроде бы понятно, но запрос упорно не хочет работать.
Для упражнения будем использовать демо-базу, подробно описанную ранее, и попробуем написать в ней запрос для поиска кратчайшего пути из одного аэропорта в другой.









 В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров. 
 Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.
Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе. В 2008 году в списке рассылки pgsql-hackers началось
В 2008 году в списке рассылки pgsql-hackers началось 
