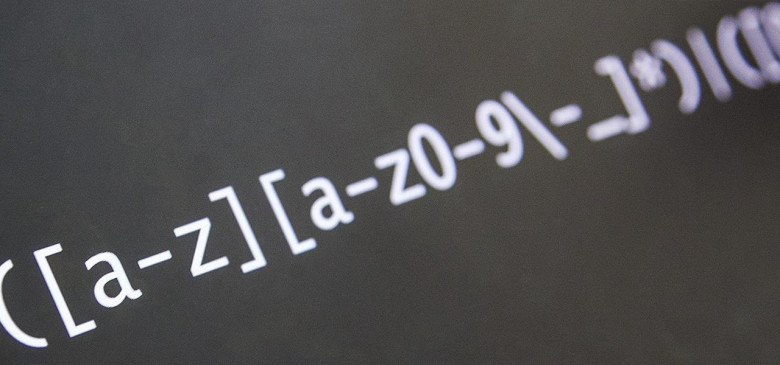История создания регулярных выражений берет свое начало с 1942 года. В то время Уолтер Питтс — американский логик, работавший, в основном, в области когнитивной психологии, работал с известным физиологом Уорреном МакКаллоком. Основой их работы были труды связанные с теоретическим построением нейронных сетей. Немного позже, американский математик Стивен Клини изучал события в сетях МакКаллока-Питтса и предложил способ описания таких событий при помощи языка регулярных выражений.
Работа Клини вышла в середине 50-х годов двадцатого века. Научные труды были бы забыты, но американский программист Кен Томпсон в конце 60-х годов обнаружил, что регулярные выражения можно использовать для задания шаблонов поиска строк в длинных текстах. Смысл поиска заключается в том, что регулярное выражения преобразуется в конечный автомат, который производит поиск строк, которые должны соответствовать определенным шаблонам. Для построения конечного автомата Томпсон придумал специальный алгоритм, который сейчас носит название «построение Томпсона». Таким образом Кен Томпсон смог принести в мир стандарт для задания поисковых шаблонов.
Сами по себе, регулярные выражения есть ни что иное, как текстовый шаблон, который соответствует какому-то тексту. В трудах Джеффри Фридла пишется, что: «Регулярные выражения— это мощнейший инструмент, хорошо известный программистам. Однако он может быть полезен не только программистам, но и всем людям, работающим с кодом или простым текстом». При использовании регулярных выражений человеку придется работать с литералами и метасимволами. Это два существенно различающихся по своей сущности понятия. Литералы – это обычные символы, т.е. при записи в строках регулярного выражения они интерпретируются так, как они записаны. Примером литералов в регулярных выражениях может быть любая буквенная последовательность. В свою очередь, метасимволы интерпретируются при поиске особым образом. Примером может служить символ «*», который задает последовательность любого количества литералов.