
Расчет и анализ корреляционного отношения средствами Python
21 мин
Расчет и анализ корреляционного отношения средствами Python.
Расчет и анализ корреляционного отношения средствами Python.

В этой заметке я буду использовать новые асинхронные возможности ORM-слоя вместе с новыми запросами в стиле 2.0. Мы создадим простое FastAPI-приложение с двумя маршрутами. Один — для добавления городов и их жителей, а другой — для вывода списка наиболее населенных объектов.
Каждый встреченный человек однажды может вам помочь.
Если поддерживать контакт с людьми, переодически о себе напоминая, есть немалая вероятность что они могут оказаться вам полезны. В обратном же случае такая вероятность просто исчезает. Нет связи, нет пользы.

Я часто пользуюсь функциями для работы с большими данными. Они позволяют упросить и ускорить работу. Некоторые я нашел на просторах интернета, другие написал сам. Сегодня хочу поделиться четырьмя из них, может кому-то будет полезно.

Относительная доступность методов секвенирования ДНК и большое количество доступной в открытых источниках генетической информации сделала актуальной разработку нейронных сетей, предназначенных для анализа цепочек ДНК и поиска корреляций между признаками и геномной последовательностью. В статье мы рассмотрим основы кодирования генетической информации и обсудим дополнение от исследовательской команды генетики Google Nucleus для Tensorflow, который позволяет считывать основные форматы кодирования генетической информации и представлять их в виде набора данных, которые могут быть проанализированы с использованием тензорных графов на основе Tensorflow.

Добрый день дорогие друзья, в данной статье я описываю Евклидову метрику или, как её еще называют Евклидово расстояние.
Евклидово расстояние - это расстояние между двумя точками. Расстояние между двумя точками в свою очередь вычисляется по теореме Пифагора. Это можно увидеть на Рис.1 Расстояние между двумя точка по теореме Пифагора.


Всем привет! Гуляя по Хабру, мне ни разу не доводилось обнаружить статью на тему Django + PWA. А ведь тема интересная (лично мне пришлось потратить 4 дня на то, чтобы с ней разобраться). И дабы сэкономить ваше время, в данной статье я попытался представить достаточно простой способ для создания прогрессивного веб приложения (PWA) вместе с Django без сторонних библиотек.

Маленький совет из будущего: «В данной статье будут затронуты некоторые понятия, о которых я писал раньше, так что для полного понимания темы, советую прочитать и предыдущую статью»На самом деле, на хабре было множество публикаций по этой теме, но все они говорят о разных вещах. Давайте разберёмся и соберём всё в одну кучку, для полноценного понимания картины мира.

Эта статья только первая из цикла "прохожу тестовые задания". Подобными заметками я хочу показать другим начинающим программистам с чем им придется столкнуться при собеседованиях на работу. Сам я изучаю питон(и не только) уже порядка 4 лет, но это только теория с практикой на своих пет проектах, что как оказалось с реальным программированием не имеет ничего общего. Итак хватит лирики.

Операторы являются основными строительными блоками DAG Airflow. Это классы, которые содержат логику выполнения единичной работы.
Вы можете использовать операторы в Airflow, создав их экземпляры в задачах. Задача определяет работу, выполняемую оператором в контексте DAG.
Чтобы просмотреть и выполнить поиск по всем доступным операторам в Airflow, посетите Astronomer Registry. Ниже приведены примеры операторов, которые часто используются в проектах Airflow.

Переход на новый язык — это всегда большой шаг. Особенно, если этим языком владеет только один член команды. В начале этого года мы поменяли основной язык программирования в Stream — с Python на Go. В этой статье я приведу 9 причин почему — и 3 минуса, выявленных в процессе.

Качественная визуализация данных не менее важна для анализа данных, чем методы математической обработки. На сегодняшний день существуют десятки (если не сотни) библиотек для визуализации наборов данных на Python, но иногда в них встречаются уникальные возможности и хотелось бы иметь возможность объединить различные инструменты в единой панели. В статье мы рассмотрим основы библиотеки panel для реализации реактивной модели интерактивных визуализаций и попробуем объединить визуализации из разных библиотек в одном dashboard.

Я решил поставить DHCP сервер на Linux, но была небольшая проблема, у нас не было текущего DHCP сервера (все ip были статическими), карты сети, списка ip и mac адресов. Я сканировал сеть получил список mac и ip, распечатал и мы с коллегой пошли записывать фамилии тех, у кого эти mac адреса. Потом я внес все это в таблицу excel (таблица 1).

Вот вам задача: надо проверить, входит ли число 200 миллионов в диапазон от 0 до 1 миллиарда. Знаю, что на Python её решение выглядит до крайности примитивно — достаточно воспользоваться функцией any и списковым включением:

Задача классификации текста уже давно является устоявшейся во многих компаниях. Она используется для определения настроения клиентов, разделение документов на заранее известные темы, детекции фейковых новостей и т.д. Сегодня я представлю state of the art подход для решения задачи бинарной классификации, а именно детекция сообщений, в которой присутствует жалоба на сотрудника.
А также сравню по точности два подхода - Fine-Tune Bert и получение предобученных эмбеддингов и их классификация с использованием полносвязной нейронной сети.

Всем привет!
В данной статье описан мой опыт создания sneakernet-сети, мотивация, побудившая написать данное ПО, общее описание работы, бенчмарки, а также ссылки на сторонние ресурсы, где можно почитать документацию и скачать исходный код и готовую скомпилированную сборку.

Полное руководство по созданию DAG в Apache Airflow DAG, позволяющих создать конвейер данных из разных источников, запускаемый в определенные периоды времени с заданной логикой. Первая часть. Источник: DAGs: The Definitive Guide от astronomer.io
Добро пожаловать в полное руководство по Apache Airflow DAG, представленное командой Astronomer. Эта электронная книга охватывает все, что вам нужно знать для работы с DAG, от строительных блоков, из которых они состоят, до рекомендаций по их написанию, динамической генерации, тестированию, отладке и многому другому. Это руководство, написанное практикующими для практикующих.

Язык Python (правильно это читается "Пайтон", но в русскоязычном сообществе так же прижилось и прочтение "Питон", мне оно тоже больше по душе ;) в последнее время получил очень большую популярность в среде непрограммистов по двум причинам:
- лёгкий синтаксис, очень близкий к естественным языкам и математическому мышлению;
- огромное количество различных библиотек (модулей), написанных как на самом питоне, так и на более быстрых языках С/С++ и Фортран.
Хотя для изучения основ Питона есть очень много хорошей литературы, в том числе и на русском языке, вопросы использования многих модулей описаны недостаточно. Особенно тяжело здесь русскоязычным инженерам. Этой статьёй я хочу начать цикл туториалов, в которых я поделюсь своим опытом использования языка Питон в практической инженерной деятельности. В настоящем туториале речь пойдёт о модуле Pint, который сильно упрощает манипулирование физическими величинами.
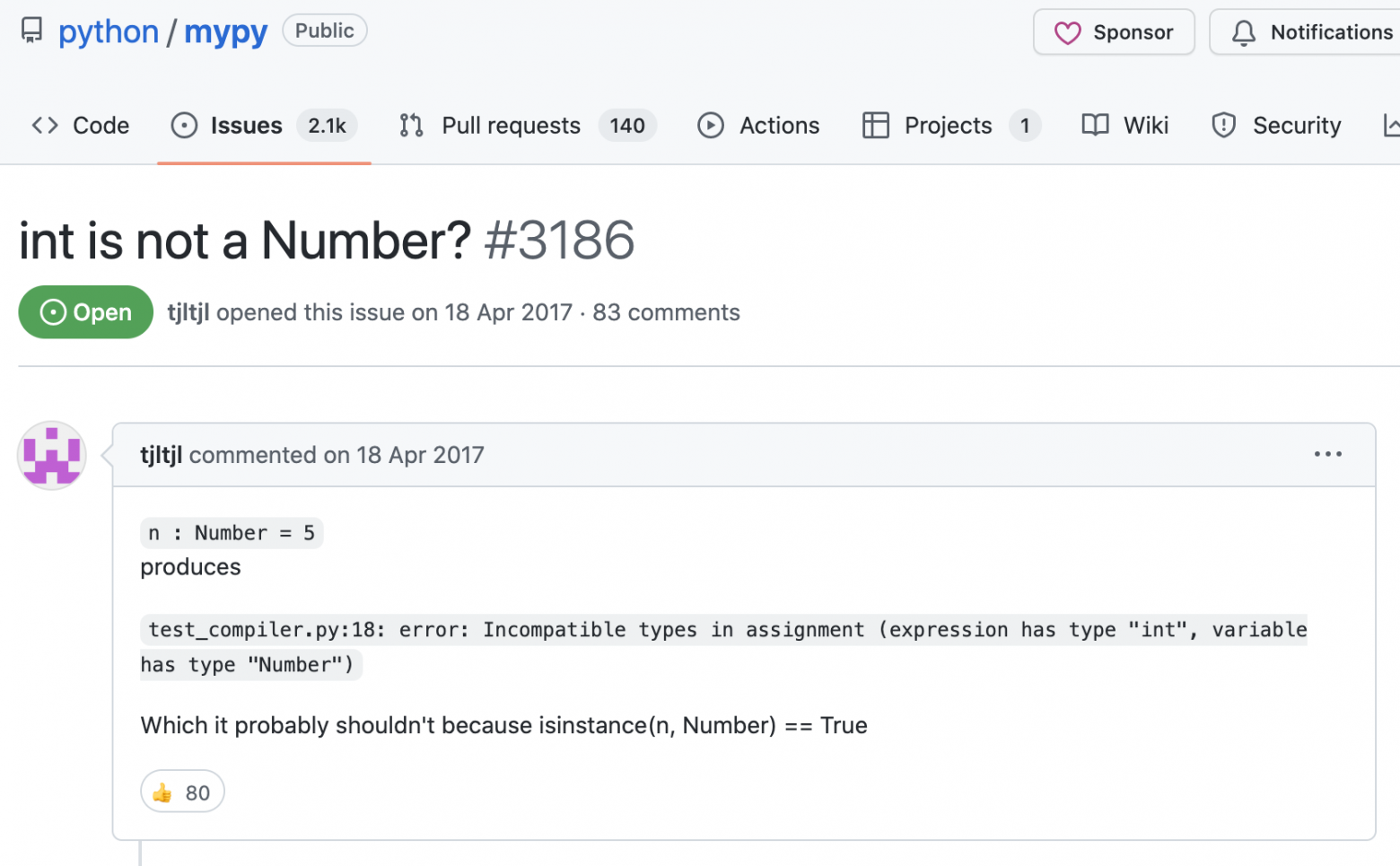
Если вы когда-нибудь чувствовали, что вы погрязли в совещаниях и обсуждениях, которые всё длятся и длятся, а решения проблемы всё нет, знайте: в mypy есть 5-летний issue, о том что целое число не является числом.
В статье рассмотрим этот и несколько других забавных примеров того, что допустимо и нет использовать в python с точки зрения mypy и самого интерпретатора.